- 我的电脑系统:Windows 10 64位
- SQL Server 软件版本: SQL Server 2014 Express
本篇博客里面使用了 scott 库,如何你现在还没有添加这个库到你的服务器里面,请在查看本篇博客前,访问这篇博文来在你的服务器里面附加scott库。
having — 对分组之后的信息进行过滤
1
2
3
4
5
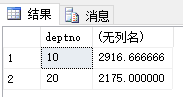
| --输出部门平均工资大于2000的部门的部门编号,部门的平均工资
select deptno, avg(sal)
from emp
group by deptno
having avg(sal)>2000;
|
加入别名。
1
2
3
4
5
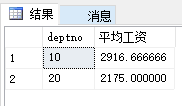
| --判断下列sql语句是否正确
select deptno, avg(sal) as "平均工资"
from emp
group by deptno
having avg(sal) > 2000
|
1
2
3
4
5
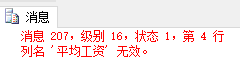
| --error
select deptno, avg(sal) as "平均工资"
from emp
group by deptno
having "平均工资" > 2000
|
正确的指令:
sql
select deptno, avg(sal)
from emp
where ename not like '%A%'
group by deptno
having avg(sal) > 2000
1
2
3
4
5
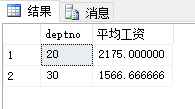
| --以部门编号分组后,显示组内元组大于3个元组的部门编号和平均工资
select deptno, avg(sal) as "平均工资"
from emp
group by deptno
having count(*) > 3
|
1
2
3
4
5
| --error
select deptno, avg(sal) as "平均工资"
from emp
group by deptno
having ename like '%A%'
|

1
2
3
4
| select deptno, avg(sal) as "平均工资"
from emp
group by deptno
having deptno>1
|
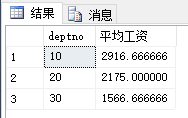
having 和 where 的异同
1
2
3
4
5
6
7
| --把姓名不包含`A`的所有的员工按部门编号分组,
--统计输出部门平均工资大于2000的部门的部门编号、部门的平均工资
select deptno, avg(sal)
from emp
where ename not like '%A%'
group by deptno
having avg(sal) > 2000
|
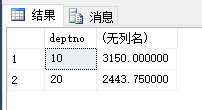
1
2
3
4
5
6
7
| --把工资大于2000,
--统计输出部门平均工资大于3000的部门的部门编号、部门的平均工资、部门人数、部门最高工资
select deptno, avg(sal) "平均工资", count(*) "部门人数", max(sal) "部门最高工资"
from emp
where sal > 2000 --where是对原始的记录过滤
group by deptno
having avg(sal) > 3000 --对分组之后的记录过滤
|
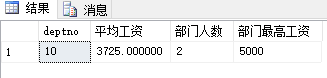
如果参数的顺序变化了,执行的时候会不会受到影响?执行下面的指令,你就会知道答案。
1
2
3
4
5
6
| --error
select deptno, avg(sal) "平均工资", count(*) "部门人数", max(sal) "部门最高工资"
from emp
group by deptno
having avg(sal) > 3000
where sal > 2000
|
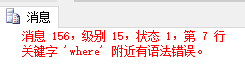
总结: 所有select 的参数的顺序是不允许变化的(所有的参数的位置都是固定的,你可以省略某个参数,但是不能变。),否则编译时出错。
having 和 where 的异同:
- 相同: 都是对数据过滤,只保留有效的数据。
where 和 having 一样,都不允许出现字段的别名,只允许出现最原始的字段的名字。
1
2
3
4
| --error where子句不应该出现聚合函数
select deptno, avg(sal)
from emp
where avg(sal) > 2000 --error 因为where是对原始的数据过滤,不能使用聚合函数
|
- 不同:
where 是对原始的记录过滤,having 是对分组之后的记录过滤。where 必须得写在having的前面,顺序不可颠倒,否则运行出错。
总结 having 的用法
having 子句是用来对分组之后的数据进行过滤。因此使用having时通常都会先使用 group by。- 如果没有使用
group by ,而使用了 having,则意味着 having 把所有的记录当做一组来进行过滤。
1
2
3
| select count(*)
from emp
having avg(sal) > 1000
|
having 子句出现的字段必须得是分组之后的组的整体信息。having 子句不允许出现组内的详细信息。
1
2
3
4
| --error
select deptno avg(sal) as "平均工资", job
from emp
group by deptno
|
1
2
3
4
| --OK
select deptno avg(sal) as "平均工资", count(*) as "部门人数"
from emp
group by deptno
|
尽管 select 字段中可以出现别名。但是having 子句中不能出现字段的别名,只能使用字段最原始的名字。(原因不得而知。)
就是上面说的:having 和 where 的异同 。(这里不重复说明了。)