开发环境
Python第三方库:lxml、Twisted、pywin32、scrapy
Python 版本:python-3.5.0-amd64
PyCharm软件版本:pycharm-professional-2016.1.4
电脑系统:Windows 10 64位
如果你还没有搭建好开发环境,请到这篇博客 。
1 知识点:scrapy 爬虫项目的创建及爬虫的创建
1.1 scrapy 爬虫项目的创建
接下来我们为大家创建一个Scrapy爬虫项目,并在爬虫项目下创建一个Scrapy爬虫文件。
1
scrapy startproject <projectname>
1.2 scrapy 爬虫文件的创建
1
2
cd demo
scrapy genspider -t basic <filename> <domain>
更多 Scrapy 命令的介绍请到这篇博客 查看。
2 实例:爬取百度标题和CSDN博客
我们创建一个爬虫项目,在里面创建一个爬虫文件来爬取百度,并再创建一个爬虫文件爬取CSDN博客文章。
先创建一个Scrapy爬虫项目:
1
scrapy startproject firstDemo
输出:
1
2
3
4
5
6
7
8
9
D:\WorkSpace\python_ws\python-large-web-crawler>scrapy startproject firstdemo
New Scrapy project 'firstdemo', using template directory 'c:\\users\\aobo\\appdata\\local\\programs\\python\\python35\\lib\\site-packages\\scrapy\\templates\\project', created in:
D:\WorkSpace\python_ws\python-large-web-crawler\firstdemo
You can start your first spider with:
cd firstdemo
scrapy genspider example example.com
D:\WorkSpace\python_ws\python-large-web-crawler>
2-1.1 使用Scrapy爬虫 爬取百度标题
创建一个爬虫文件来爬取百度
1
2
cd firstDemo
scrapy genspider -t basic baidu baidu.com
输出:
1
2
3
4
5
6
7
D:\WorkSpace\python_ws\python-large-web-crawler>cd firstdemo
D:\WorkSpace\python_ws\python-large-web-crawler\firstdemo>scrapy genspider -t basic baidu baidu.com
Created spider 'baidu' using template 'basic' in module:
firstdemo.spiders.baidu
D:\WorkSpace\python_ws\python-large-web-crawler\firstdemo>
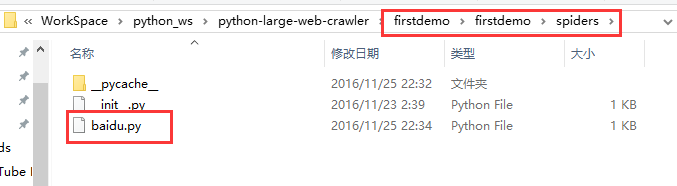
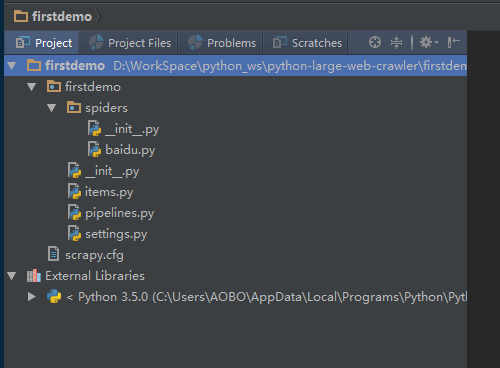
打开 PyCharm 软件,用 PyCharm 软件打开刚刚创建的 firstdemo 爬虫项目。
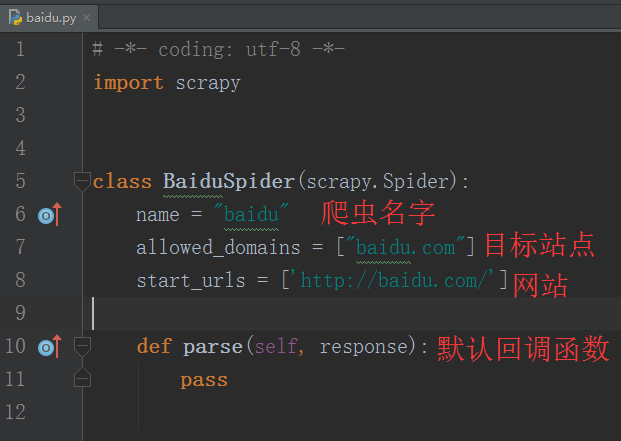
打开这 baidu.py 爬虫文件,你会看到自动生成的代码:
(源代码太多,列出重点的。)
1
2
3
4
5
<html xmlns="http://www.w3.org/1999/xhtml" class="cye-enabled cye-nm sui-componentWrap">
<head>
<title>百度一下,你就知道 </title>
</head>
</html>
源代码中的标题通过标签逐步定位: /html/head/title
2-1.3 写代码
我们现在要提取出 https://www.baidu.com/ 网页 的标题:百度一下,你就知道 。
提取信息,一般使用 xpath 或者 正则表达式 来提取。
这里我们使用 xpath 来提取,xpath 的知识点,请到这篇博客 中查看。
下面的编写代码的步骤:
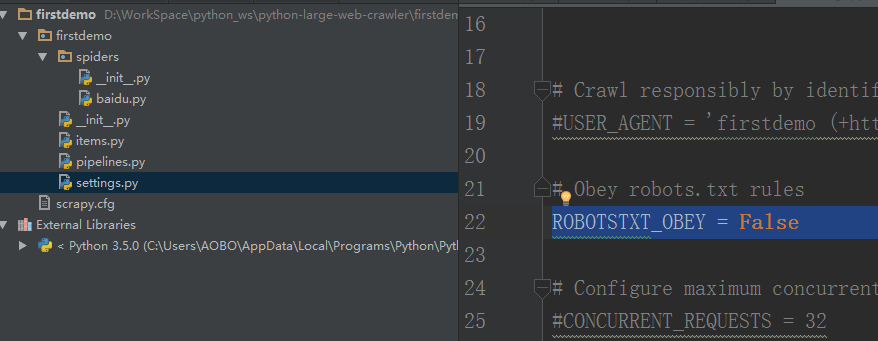
Step 1 . 设置我们的爬虫不遵循 robots.txt 规定。(什么是robots.txt规定,请到这个博客 查看。)
打开 settings.py 文件,将里面的ROBOTSTXT_OBEY 设为:False
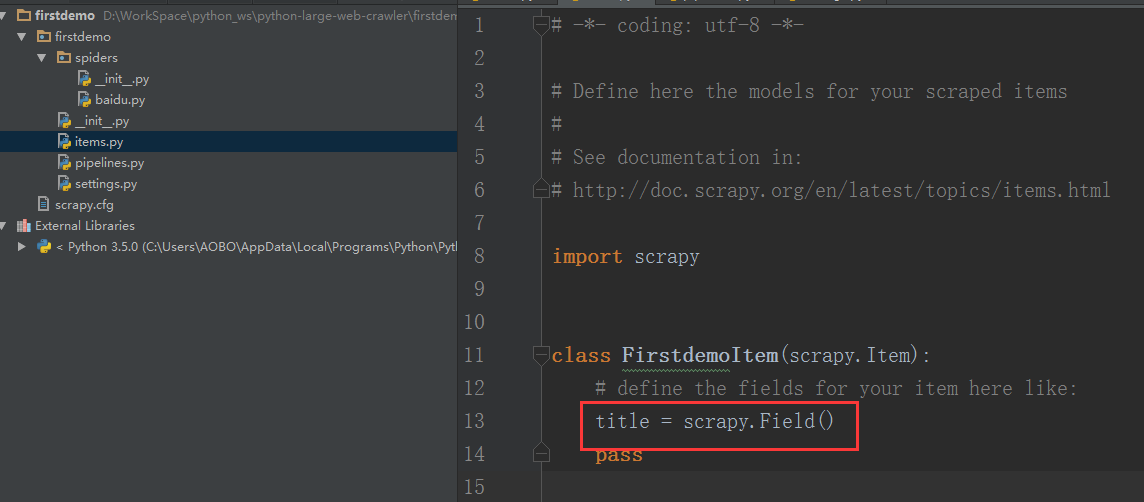
Step 2 . 打开 items.py 文件,在里面FirstdemoItem()函数里添加一项:
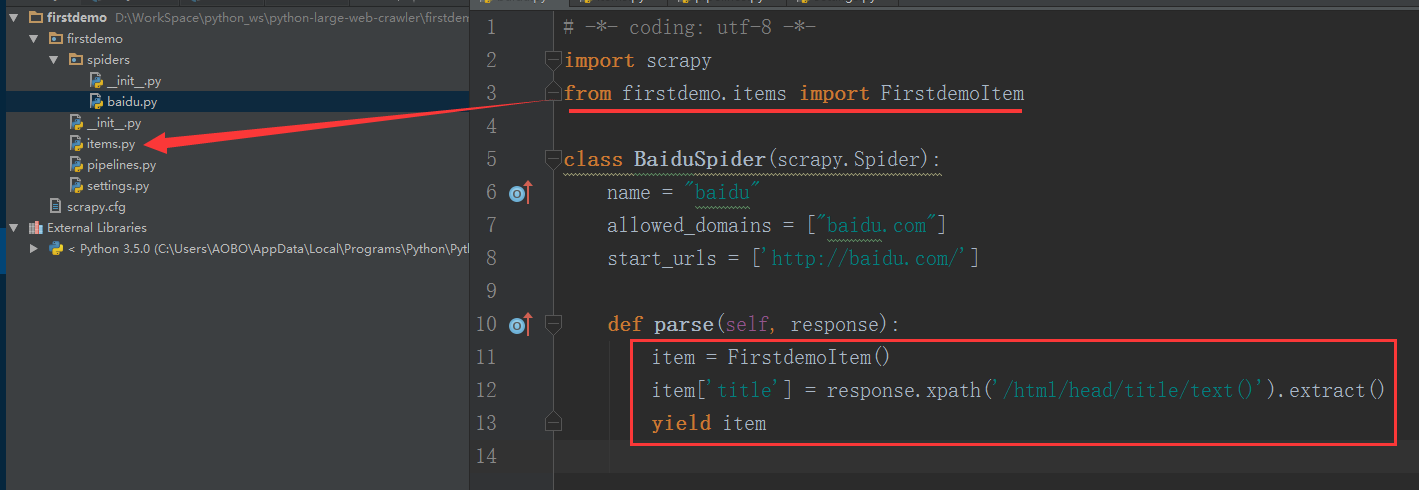
Step 3 . 在 baidu.py 文件里面,使用xpath 表达式 提取百度网页的标题。
先从核心目录(firstdemo)定位到items.py 文件里面的FirstdemoItem函数。
然后使用xpath 表达式 提取百度网页的标题。
最后,返回。
1
2
3
4
5
6
7
8
9
10
11
12
13
# -*- coding: utf-8 -*-
import scrapy
from firstdemo.items import FirstdemoItem
class BaiduSpider ( scrapy . Spider ):
name = "baidu"
allowed_domains = [ "baidu.com" ]
start_urls = [ 'http://baidu.com/' ]
def parse ( self , response ):
item = FirstdemoItem ()
item [ 'title' ] = response . xpath ( '/html/head/title/text()' ) . extract ()
yield item
Step 4 .
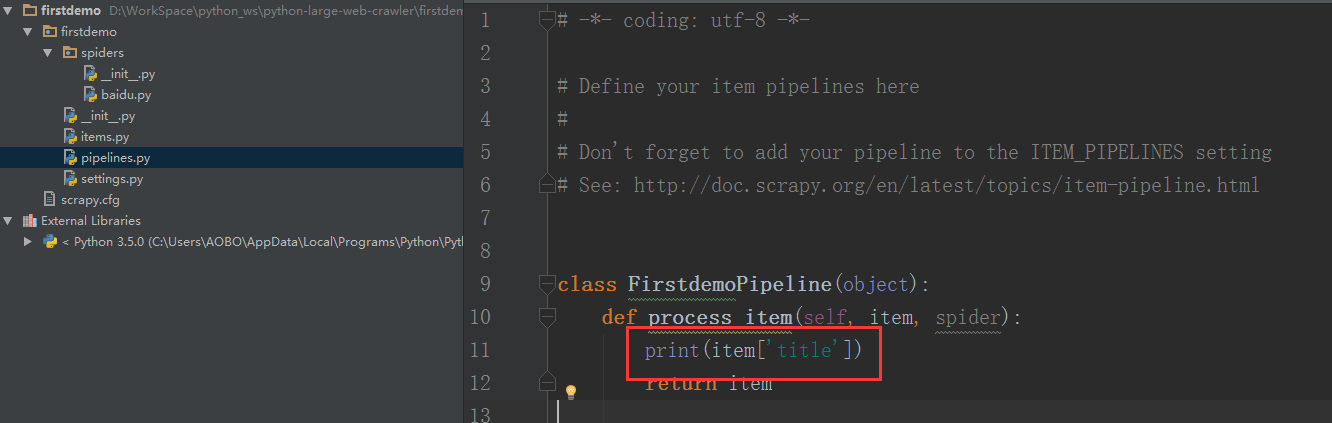
在 pipelines.py 文件里面的FirstdemoPipeline()函数,添加打印信息的代码:
但是,现在运行程序,是不能输出任何信息的,还需要做Step 5 。
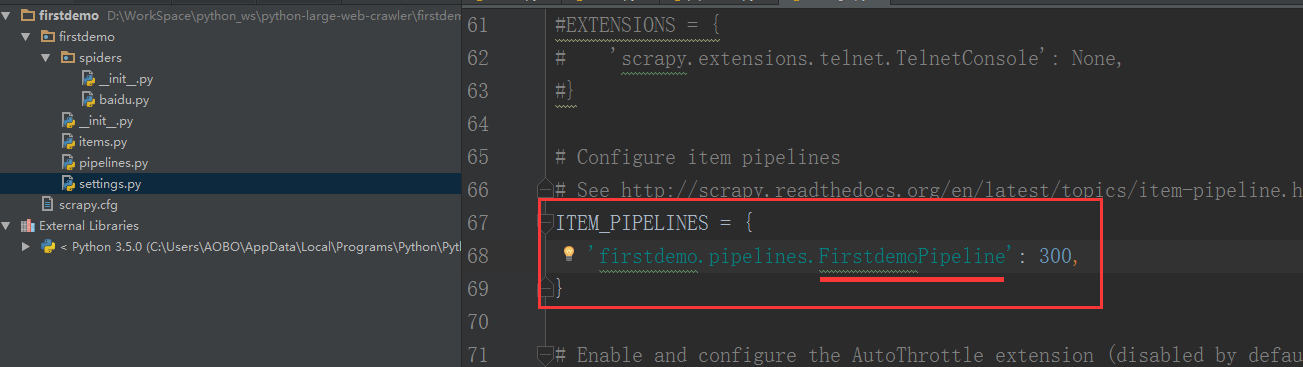
Step 5 . 开启piplines(默认piplines是关闭的。)
在 settings.py 文件,将里面的ITEM_PIPELINES 项的注释去掉。并从核心目录开始定位,定位到pipelines.py 文件里面的FirstdemoPipeline()函数 ,就应该是:firstdemo.pipelines.FirstdemoPipeline:
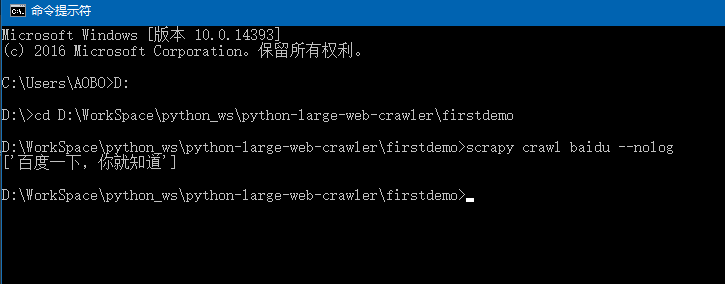
2-1.4 运行
在 DOS窗口 中,先将路劲切换到当前爬虫项目firstdemo路径下,然后在执行爬虫文件 baidy
1
2
3
D :
cd D : \WorkSpace \python_ws \python - large - web - crawler \firstdemo
scrapy crawl baidu -- nolog
2-2.1 使用Scrapy爬虫CSDN的博客文章
创建一个爬虫文件爬取CSDN博客文章。
1
scrapy genspider - t basic csdn blog . csdn . net
输出:
(网页源代码太多,这里就不贴出了。)
提取信息,一般使用 xpath 或者 正则表达式 来提取。
2-2.3 写代码
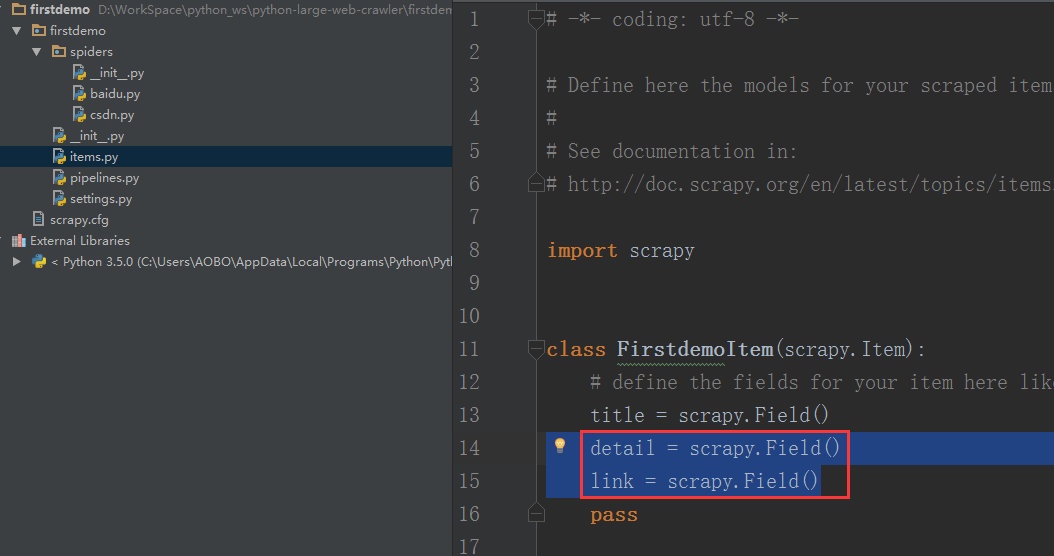
Step 1 . 在items.py 文件中的FirstdemoItem()函数中添加新的项。其他的文件会使用这几个对象:
1
2
detail = scrapy . Field ()
link = scrapy . Field ()
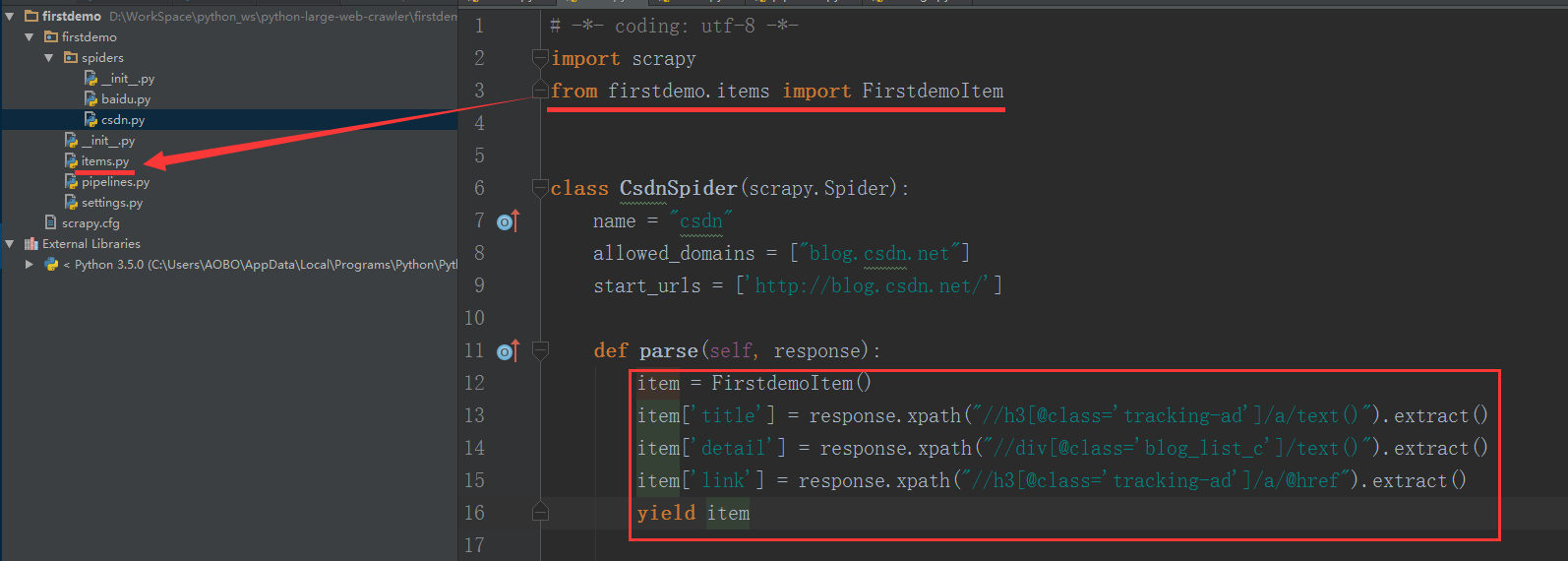
Step 2 . 在 csdn.py 文件里面,使用xpath 表达式 提取csdn博客网页的博文标题、介绍、链接地址。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# -*- coding: utf-8 -*-
import scrapy
from firstdemo.items import FirstdemoItem
class CsdnSpider ( scrapy . Spider ):
name = "csdn"
allowed_domains = [ "blog.csdn.net" ]
start_urls = [ 'http://blog.csdn.net/' ]
def parse ( self , response ):
item = FirstdemoItem ()
item [ 'title' ] = response . xpath ( "//h3[@class='tracking-ad']/a/text()" ) . extract ()
item [ 'detail' ] = response . xpath ( "//div[@class='blog_list_c']/text()" ) . extract ()
item [ 'link' ] = response . xpath ( "//h3[@class='tracking-ad']/a/@href" ) . extract ()
yield item
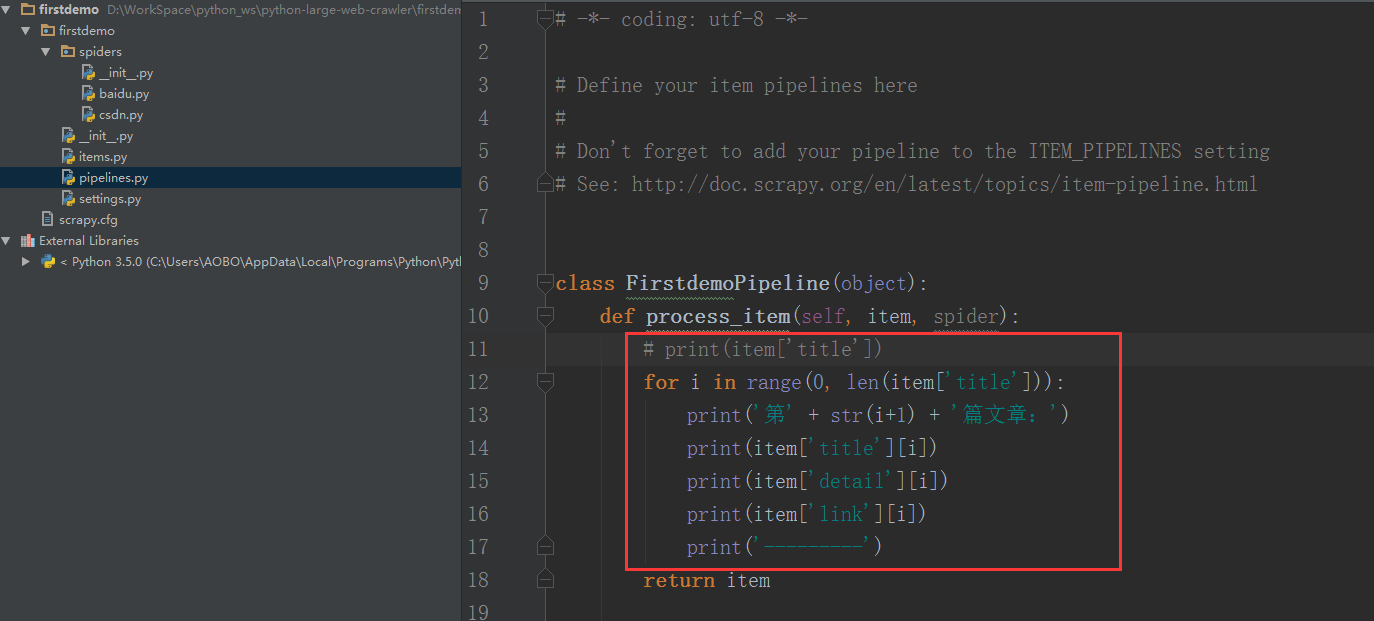
Step 3 . 在 piplines.py 文件中,添加下面的代码,输出显示爬取到的信息。
1
2
3
4
5
6
for i in range ( 0 , len ( item [ 'title' ])):
print ( '第' + str ( i + 1 ) + '篇文章:' )
print ( item [ 'title' ][ i ])
print ( item [ 'detail' ][ i ])
print ( item [ 'link' ][ i ])
print ( '---------' )
2-1.4 运行
1
scrapy crawl csdn -- nolog
执行输出的信息太少,说明程序有问题。
scrapy crawl csdn
如果你在执行的时候,找到错误提示信息:
UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 10: illegal multibyte sequence
这个问题经常会遇到,是一个常见的问题,解决办法在这里 可以找到。
print(item['detail'][i].replace(u'\xa0 ', u' '))
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
第 1 篇文章:
微信小程序:小程序,新场景
前言:我们频繁进入的地方,是场景。手机,是场景;浏览器,是场景;其实,微信,也是场景……微信要做的是占据更多用户时间、占
据更多应用场景、占据更多服务入口,这是商业本质想去垄断要做的事情。对于大家来讲, ...
http : // blog . csdn . net / liujia216 / article / details / 53350247
---------
第 2 篇文章:
Android 四大组件—— BroadcastReceiver 普通广播、有序广播、拦截广播、本地广播、 Sticky 广播、系统广播
BroadcastReceiver 普通广播、有序广播、拦截广播、本地广播、 Sticky 广播、系统广播
本篇文章包括以下内容:
前言
BroadcastReceiver 的简介
...
http : // blog . csdn . net / qq_30379689 / article / details / 53341313
---------
第 3 篇文章:
Gif 格式简要介绍
Gif 格式的介绍
为什么有的 Gif 图不能够循环播放及处理办法
http : // blog . csdn . net / shiroh_ms08 / article / details / 53347873
---------
第 4 篇文章:
win10 uwp 打包第三方字体到应用
有时候我们会把一些特殊字体打包到软件,因为如果找不到我们的字体会变为默认,现在很多字体图标我们用得好,有时候我们的应用会
用很漂亮的字体,需要我们自己打包,因为用户一般是没有字体。 UWP 使用第三方字体首 ...
http : // blog . csdn . net / lindexi_gd / article / details / 52716655
---------
第 5 篇文章:
话说智能指针发展之路
动态创建内存的管理太麻烦,于是乎,这个世界变成 11 派人:
一派人勤勤恳恳按照教科书的说法做,时刻小心翼翼,苦逼连连;
一派人忘记教科书的教导,随便乱来,搞得代码处处 bug ,后期维护骂声连连;
最 ...
http : // blog . csdn . net / jacketinsysu / article / details / 53343534
---------
第 6 篇文章:
安卓自定义控件(二) BitmapShader 、 ShapeDrawable 、 Shape
第一篇博客中,我已经对常用的一些方法做了汇总,这篇文章主要介绍 BitmapShader 位图渲染、 ComposeShader 组合渲染,然后看看 Xferm
ode 如何实际应用。不过本文还是只重写 onDraw ...
http : // blog . csdn . net / chen413203144 / article / details / 53343209
---------
第 7 篇文章:
JSTL 标签大全详解
1 、什么是 JSTL ? JSTL 是 apache 对 EL 表达式的扩展(也就是说 JSTL 依赖 EL ), JSTL 是标签语言! JSTL 标签使用以来非常方便,它与 JSP
动作标签一样,只不过它不是 JSP 内 ...
http : // blog . csdn . net / qq_25827845 / article / details / 53311722
---------
第 8 篇文章:
Android 调试大法 自定义 IDE 默认签名文件
你是否为调试第三方 SDK 时 debug 签名和 release 签名发生冲突而烦恼?你是否在 debug 时第三方功能测试通过,而 release 时无法使用?你
是否在为对接微信、支付宝、地图因签名导致的问题而烦恼? ...
http : // blog . csdn . net / yanzhenjie1003 / article / details / 53334071
---------
第 9 篇文章:
Android 图表库 MPAndroidChart ( 十二 ) ——来点不一样的,正负堆叠条形图
Android 图表库 MPAndroidChart ( 十二 ) ——来点不一样的,正负堆叠条形图
接上篇,今天要说的,和上篇的类似,只是方向是有相反的两面,我们先看下效果 实际上这样就导致了我们的代码是 ...
http : // blog . csdn . net / qq_26787115 / article / details / 53333270
---------
第 10 篇文章:
一步步手动实现热修复 ( 二 ) - 类的加载机制简要介绍
一个类在被加载到内存之前要经过加载、验证、准备等过程。经过这些过程之后,虚拟机才会从方法区将代表类的运行时数据结构转换为
内存中的 Class 。
我们这节内容的重点在于一个类是如何被加载的,所以我们从类 ...
http : // blog . csdn . net / sahadev_ / article / details / 53334911
---------
第 11 篇文章:
仿射变换详解 warpAffine
今天遇到一个问题是关于仿射变换的,但是由于没有将仿射变换的具体原理型明白,看别人的代码看的很费解,最后终于在师兄的帮助下
将原理弄明白了,我觉得最重要的是理解仿射变换可以看成是几种简单变换的复合实现,
...
http : // blog . csdn . net / q123456789098 / article / details / 53330484
---------
第 12 篇文章:
React Native 嵌入 Android 原生应用中
开发环境准备首先你要搭建好 React Native for Android 开发环境, 没有搭建好的可以参考: React Native for Android Windows 环境
搭建 用 Android ...
http : // blog . csdn . net / u011965040 / article / details / 53331859
---------
第 13 篇文章:
TCP 三次握手四次挥手详解
TCP 三次握手四次挥手详解
http : // blog . csdn . net / u010913001 / article / details / 53331863
---------
第 14 篇文章:
腾讯 Android 面经
秋招收官最后一战。
腾讯一面(电话):
自我介绍
项目,平时怎么学习?
设计模式
( 1 )知道哪些设计模式?设计模式在 Android 、 Java 中是怎么应用的,每个都说一下?
( 2 ) InputStre ...
http : // blog . csdn . net / kesarchen / article / details / 53332157
---------
第 15 篇文章:
轻松实现部分背景半透明的呈现效果
实现一个简单的呈现 / 解散动画效果,当呈现时,呈现的主要内容和背景要明显区分,背景呈现一个半透明遮罩效果,透过背景可以看到
下层 View Controller 的内容
http : // blog . csdn . net / kmyhy / article / details / 53322669
---------
第 16 篇文章:
APP 自动化框架 LazyAndroid 使用手册( 4 ) -- 测试模板工程详解
概述前面的 3 篇博文分别对 lazyAndroid 的框架简介、元素抓取和核心 API 进行了说明,本文将基于框架给出的测试模板工程,详细阐述下
使用该框架进行安卓 UI 自动化测试的步骤。
http : // blog . csdn . net / kaka1121 / article / details / 53325265
---------
第 17 篇文章:
Android 使用 getIdentifier () 方法根据资源名来获取资源 id
有时候我们想动态的根据一个资源名获得到对应的资源 id ,就可以使用 getResources () . getIdentifier () 方法来获取该 id 。然后再使用该
id 进行相关的操作。
1 、 Demo 示例
下 ...
http : // blog . csdn . net / ouyang_peng / article / details / 53328000
---------
第 18 篇文章:
Android 基于 RecyclerView 实现高亮搜索列表
这篇应该是 RecycleView 的第四篇了, RecycleView 真是新生代的宠儿能做这么多的事情。转载请注明作者 AndroidMsky 及原文链接
http : // blog . csdn . net / and ...
http : // blog . csdn . net / androidmsky / article / details / 53306657
---------
第 19 篇文章:
使用 Git Hooks 实现开发部署任务自动化
提供: ZStack 云计算 前言版本控制,这是现代软件开发的核心需求之一。有了它,软件项目可以安全的跟踪代码变更并执行回溯、完整
性检查、协同开发等多种操作。在各种版本控制软件中, git 是近年来最流行的软 ...
http : // blog . csdn . net / zstack_org / article / details / 53331077
---------
第 20 篇文章:
Andromeda OS 来了, Android 再见?
相信有部分同学已经有耳闻了,前几天炒的很火一个消息,就是 Google 要推出一种全新的操作系统,取名 Andromeda ,这款新型的操作
系统融合了 Android 和 Chrome OS ,据称已经有 ...
http : // blog . csdn . net / googdev / article / details / 53331364
---------
我用英语跟小贩交谈,突然画面一下就全暗,我回台上,终于轮我上场。