开发环境
- Python第三方库:lxml、Twisted、pywin32、scrapy
- Python 版本:python-3.5.0-amd64
- PyCharm软件版本:pycharm-professional-2016.1.4
- 电脑系统:Windows 10 64位
如果你还没有搭建好开发环境,请到这篇博客。
所有的设置都是在scrapy爬虫项目中的settings.py 文件中进行设置。
Step 1 . 设置爬虫不遵循 robots.txt协议
1 2 | |

想要了解什么是
robots.txt协议,请访问这篇博客:解析 robots.txt 文件。
Step 2 . 设置取消Cookies
1 2 | |

Cookies:
简单的说,Cookie就是服务器暂存放在你计算机上的一笔资料,好让服务器用来辨认你的计算机。当你在浏览网站的时候,Web服务器会先送一小小资料放在你的计算机上,Cookie 会帮你在网站上所打的文字或是一些选择,都记录下来。当下次你再光临同一个网站,Web服务器会先看看有没有它上次留下的Cookie资料,有的话,就会依据Cookie里的内容来判断使用者,送出特定的网页内容给你。
Step 3 . 设置用户代理值(USER_AGENT)
1 2 | |

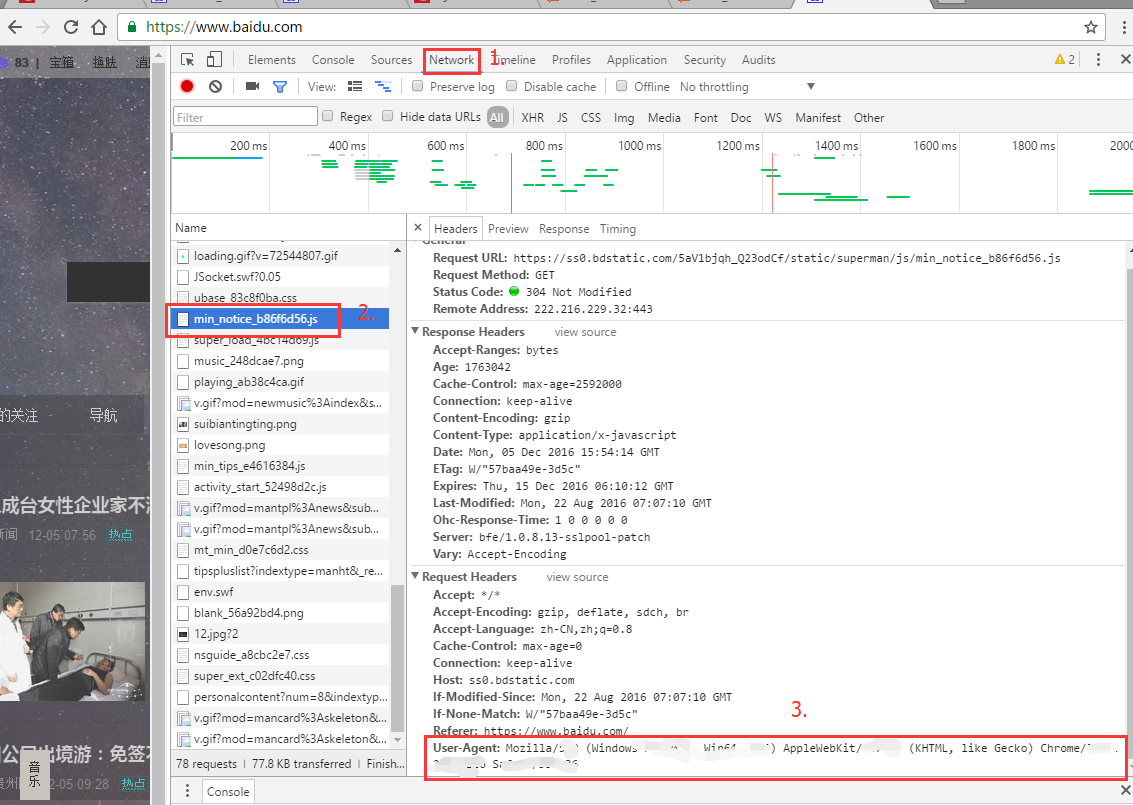
这个 用户代理可以在浏览器里面找到:
随便浏览一个网页,按F12 -> Network -> F5,随便点击一项,你都能看到有 User-agent 这一项,将这里面的内容拷贝就可以。
Step 4 . 设置IP
对于这一步,如果你没有做什么违法的事情,可以不用设置。仅仅上面的三个步骤,就可以将那些具有反爬虫机制的网站可以正常爬取了。