支持代理
- 使用的系统:Windows 10 64位
- Python 语言版本:Python 2.7.10 V
- 使用的编程 Python 的集成开发环境:PyCharm 2016 04
- 我使用的 urllib 的版本:urllib2
注意: 我没这里使用的是 Python2 ,而不是Python3
一 . 前言
在国内一些网站已经被屏蔽,比如google、Facebook等等。如果我们想要访问这些被屏蔽的网站,需要翻墙,术语叫:代理。简单的说就是,我们访问这些网站都是通过国内的服务器来访问这些网站,但是在你与服务器之间有一道长城防火墙,它会判断你访问的这个网站是不是在屏蔽列表里的网站。假如你现在访问google网站,长城防火墙就会屏蔽这个网站,不让你访问它。
那么代理又是什么呢? 简单的说就是你不是直接访问的google网站,而是访问的国外的一个服务器。你在电脑上输入google的网站后,信息的运输是这样的: 国外服务器接受到你访问的网站,它帮你访问,然后将访问得到的结果返回给你。
二 . 测试
我们可以使用 urllib2 支持代理。
1
2
3
4
5
| proxy = ...
opener = urllib2.build_opener()
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
response = opener.open(request)
|
三 . 代码
代码在这里。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| #-*- coding:utf-8 -*-
import urllib2
import chardet
import urlparse
def download(url, user_agent='wswp', proxy=None, num_retries=2):
print 'Downloading: ', url
headers = {'User-agent' : user_agent}
request = urllib2.Request(url, headers=headers)
opener = urllib2.build_opener()
if proxy:
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html = opener.open(request).read()
charset = chardet.detect(html)['encoding']
if charset == 'GB2312' or charset == 'gb2312':
html = html.decode('GBK').encode('GB18030')
else:
html = html.decode(charset).encode('GB18030')
except urllib2.URLError as e:
print 'Download error', e.reason
html = None
if num_retries > 0:
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# recursively retry 5xx HTTP errors
return download(url, user_agent, proxy, num_retries-1)
return html
|
四 . 运行
如何使用这个最新的 download() 函数。download() 函数里面的形参 proxy 究竟要传入什么?
如果直接运行:
1
| >>> download('https://www.google.co.jp/')
|
输出:
1
2
| Downloading: https://www.google.co.jp/
Download error [Errno 11002] getaddrinfo failed
|
现在,我们启动proxy代理:
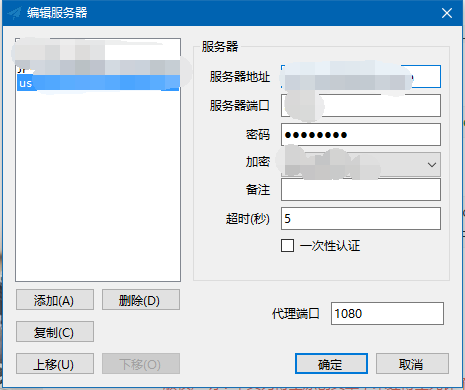
proxy 的本地端口为:127.0.0.1:1080
所以,我们给download() 函数的 proxy 参数的值设置为:127.0.0.1:1080
1
| >>> download('https://www.google.co.jp/', proxy='127.0.0.1:1080')
|
成功输出了google日本的网站源代码:
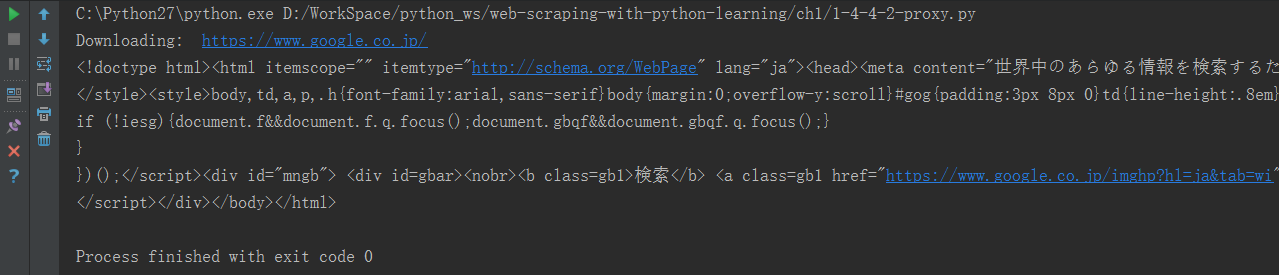
五 . 讲解代码中重点部分
1
2
3
| if proxy:
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
|
如果用户给proxy参数赋值了,那么就执行里面的代码。
其中urlparse.urlparse(url).scheme 得到的是网页的协议类型,比如:http、https、ftp等等。
所以proxy_params = {urlparse.urlparse(url).scheme: proxy}这句代码现在这个情况就等于:proxy_params = {'https', '127.0.0.1:1080'}。所以,proxy_params是一个字典,里面存放在代理的端口号。
在urllib2包中有ProxyHandler类,通过此类可以设置代理访问网页。
所以,上面完整的代码所执行的功能,和下面这一小段代码执行所得到的效果是一样的:
1
2
3
4
5
6
7
8
9
10
11
| #coding=utf8
import urllib2
import chardet
proxy = urllib2.ProxyHandler({'https': '127.0.0.1:1080'})
opener = urllib2.build_opener(proxy)
html = opener.open('https://www.google.co.jp/').read()
charset = chardet.detect(html)['encoding']
print html.decode(charset).encode('GB18030')
|
参考网站:
http://outofmemory.cn/code-snippet/2625/python-urllib2-usage-ProxyHandler-through-Proxy-call-wangye