GUI-Evernote-Auto-converted-to-Octopress-local-site-blog-and-CSDN-blog
[TOC]
开发环境:
Python 版本: Python3.5.0
PyCharm 版本:PyCharm 2016.1.4
Windows 10 64位 系统
程序设计流程
用一个变量存放 Octopress 博客的文件名。比如:folder_name = '2016-11-27-demo'
在与马克飞象笔记文件夹 (evernote_folder_name)同一路径(root_directory)下,创建一个文件夹,取名为folder_name变量
将马克飞象笔记文件夹 (evernote_folder_name)里面的所有图片全部复制到刚刚新创建的folder_name 文件夹(路径)里面。
将马克飞象笔记文件夹 (evernote_folder_name)里面的笔记文件(.md文件),复制一份放到root_directory路径下,并将其名字重命名为:folder_name变量,并将其后缀修改为:.markdown
读取folder_name.markdown 文件,将里面的图片链接替换为Octopress 本地链接的形式
删除笔记里面的 第一个标题(# xxx) 和 笔记本(@(xxx))(方法:以后记马克飞象笔记,第1行是标题,第3行是 归宿笔记本。所以,我们只需要简单的将前3行删除就可。)
添加Octopress 博客前缀
将最终得到的Octopress博文文件(.markdown后缀文件)保存为UTF-8无BOM编码文件
之前创建文件夹folder,现在加一个条件:如果文件夹已经存在,则不用创建
自动检测这个博客是:仅仅一个文件(.md),还是一个文件夹(就是检测这个博文里面有没有图片)
给定马克飞象笔记文件(.md文件)路径,自动获取root_directory路径
自动检测这个博客是:仅仅一个文件(.md),还是一个文件夹 和 给定马克飞象笔记文件(.md文件)路径,自动获取root_directory路径 和 evernote_folder_name名字 的代码如下:
如果马克飞象笔记只是一个文件,我们就不进行创建文件夹、复制图片和文件内图片链接的修改的操作
将整个evernoteToOctopressBlog.py封装成一个类:EvernoteToOctopressBlog
将evernoteToOctopressBlog.py文件写成一个工具(命令行工具),可以向里面传入命令行参数
基本完成了
这样,程序的功能就都完成了。
Python 创建文件夹
参考网站:
1
2
3
4
5
6
7
8
# -*- coding: utf-8 -*-
import os
folder_name = '2016-11-27-demo'
root_directory = 'D:/WorkSpace/test_ws/'
os . mkdir ( root_directory + folder_name )
注意:如果想要创建的文件夹是已经存在的,那么执行上面的程序会出现下面的错误:FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。
所以这段代码容易出现错误:如果文件夹已存在或者文件夹名中有不允许使用的字符时,os.mkdir()函数都会执行失败。所以,这段代码需要进行异常处理:
参考网站:Python 异常处理
1
2
3
4
try :
os . mkdir ( root_directory + folder_name )
except OSError :
pass
这样,在运行程序的时候就不会再出现错误了。但是当你给定的文件名中有非法字符时,创建文件夹是不会成功的,但是程序不会报错。
Python 复制图片
参考网站:
将马克飞象笔记文件夹 里面的所有图片全部复制到刚刚新创建的folder_name 文件夹(路径)里面。
python自带的第三方库:shutil 可以实现文件的复制操作,但是它只能一次复制一个文件。所以我们不使用这个shutil 模块来做复制文件的操作。
我们使用python调用Windows系统DOS命令行里面的copy 工具来继续文件的复制。
下面的代码可以将马克飞象笔记文件夹 里面的所有图片复制到folder_name文件夹里面:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# -*- coding: utf-8 -*-
import os
folder_name = '2016-11-27-demo'
evernote_folder_name = 'Python3 大型网络爬虫实战 003 — scrapy 大型静态图片网站爬虫项目实战 — 实战:爬取 169美女图片网 高清图片 — Over — 2016年11月26日 星期六'
root_directory = r'D:\WorkSpace\test_ws \\ '
try :
os . mkdir ( root_directory + folder_name )
except OSError as err :
print ( 'File error: ' + str ( err ))
pass
copy_img_command = 'copy "' + root_directory + evernote_folder_name + r'\*.png" "' + root_directory + folder_name + r'\"'
# print(copy_img_command)
os . system ( copy_img_command )
其实,代码中的 os.system(copy_img_command) 这段代码就是等价于:在 DOS 窗口执行:copy "D:\WorkSpace\test_ws\\Python3 大型网络爬虫实战 003 — scrapy 大型静态图片网站爬虫项目实战 — 实战:爬取 169美女图片网 高清图片 — Over — 2016年11月26日 星期六\*.png" "D:\WorkSpace\test_ws\\2016-11-27-demo\" 这个指令。
经验:我发现了两件事:
1 . 在DOS 里面,执行下面的命令,有的是对的,有的是错的:
1
2
3
4
5
6
7
8
# Succesfull
copy "D:\WorkSpace \t est_ws\Python3 大型网络爬虫实战 003 — scrapy 大型静态图片网站爬虫项目实战 — 实战:爬取 169美女图片网 高清图片 — Over — 2016年11月26日 星期六\*.png" "D:\WorkSpace \t est_ws \201 6-11-27-demo \"
# Succesfull
copy "D:\WorkSpace \t est_ws \\ Python3 大型网络爬虫实战 003 — scrapy 大型静态图片网站爬虫项目实战 — 实战:爬取 169美女图片网 高清图片 — Over — 2016年11月26日 星期六\*.png" "D:\WorkSpace \t est_ws \\ 2016-11-27-demo \"
# error
copy "D:/WorkSpace/test_ws/Python3 大型网络爬虫实战 003 — scrapy 大型静态图片网站爬虫项目实战 — 实战:爬取 169美女图片网 高清图片 — Over — 2016年11月26日 星期六/*.png" "D:/WorkSpace/test_ws/2016-11-27-demo/"
# error
copy "D://WorkSpace//test_ws//Python3 大型网络爬虫实战 003 — scrapy 大型静态图片网站爬虫项目实战 — 实战:爬取 169美女图片网 高清图片 — Over — 2016年11月26日 星期六//*.png" "D://WorkSpace//test_ws//2016-11-27-demo//"
总结:
\是一个特殊字符,它不能再字符串中正常的显示,如果必须显示,就这样写:\\DOS 命令里面指定文件路径时,只能使用\,不能使用/ 和 // ,使用这两个都是错的,都会导致 DOS 找不到指定的文件路径在DOS 命令里面,指定文件路径的 \ ,你写成 \\ 或者 \\\ 或者 \\\\\\ … 对是可以正常执行的,不会出现错误。
2 . 同时,我发现:
python 的字符串前面加上r,说明这个字符串是raw string,即无需转义的字符串,意思就是这个字符串里面有什么就是什么。
但是我发现了python的一个bug:
1
2
3
# error
str = r'D:\WorkSpace\test_ws \'
# 经验:就算是在字符串前面加上了 r ,字符串最后一个字符也不能是 /
1
2
3
4
# succes
str = r'D:\WorkSpace\test_ws \\ '
print ( str )
# 输出:D:\WorkSpace\test_ws\\
1
2
3
4
# succes
str = 'D:\WorkSpace \t est_ws \\ '
print ( str )
# 输出:D:\WorkSpace est_ws\
Python 复制文件,并对副本文件重命名
1
2
3
copy_file_command = 'copy "' + root_directory + evernote_folder_name + r' \\ ' + evernote_folder_name + '.md" "' + root_directory + folder_name + '.markdown"'
# print(copy_file_command)
os . system ( copy_file_command )
打开马克笔记的拷贝文件(.markdown后缀)
参考网站:
1
2
3
4
5
evernote_file_path = root_directory + folder_name + '.markdown'
evernote_file = open ( evernote_file_path , 'rt' , encoding = 'utf-8' )
evernote_data = evernote_file . read ()
evernote_file . close ()
print ( evernote_data )
替换图片的链接
使用正则表达式先提取出原来的图片链接。再将这个链接修改为Octopress 本地形式的链接。最后进行替换。
1
2
3
4
5
6
7
8
image_local_path = re . findall ( '!\[Alt text\]\((.*?)\)' , evernote_data , re . S )
# print(image_local_path)
image_relative_path = []
for i in range ( len ( image_local_path )):
image_relative_path . append ( '/images/' + folder_name + image_local_path [ i ][ 1 :])
# print(image_relative_path[i])
evernote_data = evernote_data . replace ( image_local_path [ i ], image_relative_path [ i ])
print ( evernote_data )
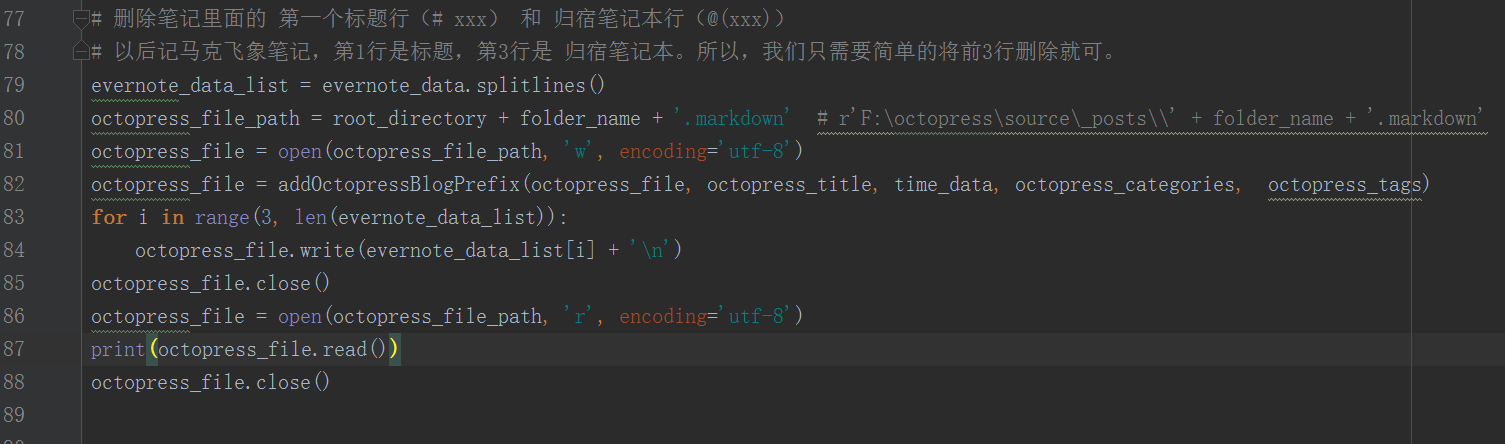
删除笔记里面的 第一个标题(# xxx) 和 笔记本(@(xxx))
我是这样设计的,我们今后写马克笔记定一个规则:
以后记马克飞象笔记,第1行是标题,第3行是 归宿笔记本。所以,我们只需要简单的将前3行删除就可。
参考网站:
1
2
3
4
5
6
7
8
9
evernote_data_list = evernote_data . splitlines ()
octopress_file_path = root_directory + folder_name + '.markdown' # r'F:\octopress\source\_posts\\' + folder_name + '.markdown'
octopress_file = open ( octopress_file_path , 'w' )
for i in range ( 3 , len ( evernote_data_list )):
octopress_file . write ( evernote_data_list [ i ] + ' \n ' )
octopress_file . close ()
octopress_file = open ( octopress_file_path , 'r' )
print ( octopress_file . read ())
octopress_file . close ()
运行:
添加Octopress 博客前缀
1
2
3
4
5
6
7
8
9
10
11
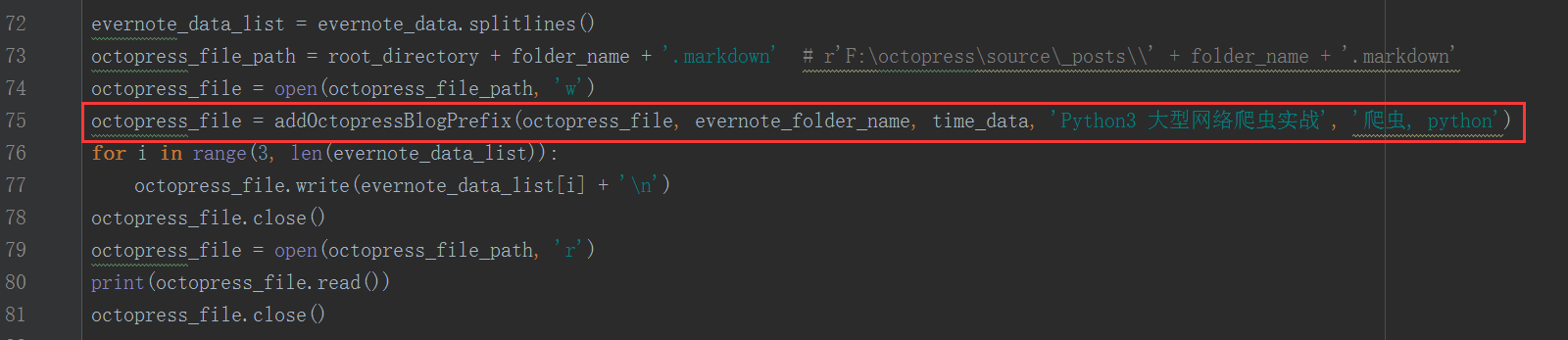
def addOctopressBlogPrefix ( octopress_file , title , data , categories , tags ):
octopress_file . write ( '---' + ' \n ' )
octopress_file . write ( 'layout: post' + ' \n ' )
octopress_file . write ( 'title: "' + title + '"' + ' \n ' )
octopress_file . write ( 'date: ' + data + ' +0800' + ' \n ' )
octopress_file . write ( 'comments: true' + ' \n ' )
octopress_file . write ( 'sharing: true' + ' \n ' )
octopress_file . write ( 'categories: [' + categories + ']' + ' \n ' )
octopress_file . write ( 'tags: [' + tags + ']' + ' \n ' )
octopress_file . write ( '---' + ' \n ' )
return octopress_file
使用这个addOctopressBlogPrefix()函数:
这个系统时间是这样得到的:(参考网站 )
1
2
3
4
import time
# 格式化成2016-03-20 11:45:39形式
time_data = time . strftime ( "%Y-%m- %d %H:%M:%S" , time . localtime ())
# print(time_data)
将最终得到的Octopress博文文件(.markdown后缀文件)保存为UTF-8无BOM编码文件
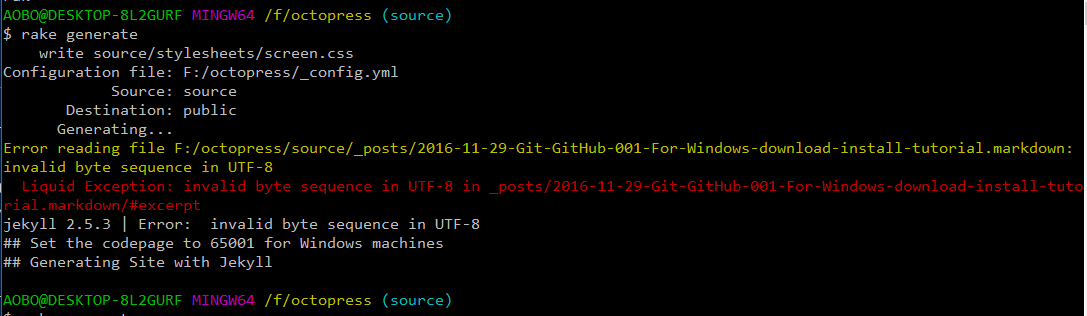
如果现在将这个文件和图片转移到Octopress站点路径里面,然后执行rake generate命令会出现下面这个错误:
1
2
Error reading file F : / octopress / source / _posts / xxxx . markdown : invalid byte sequence in UTF - 8
Liquid Exception : invalid byte sequence in UTF - 8 in _posts / xxxx . markdown / #excerpt
这个错误时说:这个文件xxxx.markdown它的编码不是标准的UTF-8无BOM编码方式编辑的文件。
所以,为了解决这个问题,我们需要将输出的Octopress 博文文件(.markdown后缀文件)在保存的时候将其转换为以Utf-8无BOM编码方式编码的文件。
其实很简单,我们只需要将下面这行代码:
1
octopress_file = open ( octopress_file_path , 'w' )
修改为:
1
octopress_file = open ( octopress_file_path , 'w' , encoding = 'utf-8' )
这样octopress_file文件就是以Utf-8无BOM编码方式编码的文件。
我们也看到了,其实不是将octopress_file保存为以Utf-8无BOM编码方式编码的文件,而是创建这个一个以Utf-8无BOM编码方式编码的文件 octopress_file。
虽然已经成功的将最终得到的Octopress博文文件(.markdown后缀文件)保存为UTF-8无BOM编码文件。但是在执行 print(octopress_file.read()) 这句代码的时候,出现了UnicodeDecodeError 错误,如下。
1
2
print ( octopress_file . read ())
UnicodeDecodeError : 'gbk' codec can 't decode byte 0x8b in position 75: illegal multibyte sequence
哦,这个问题也非常容易解决,可以说现在不在是一个难问题了。
解决办法:将print(octopress_file.read())这行代码的上一行:
1
octopress_file = open ( octopress_file_path , 'r' )
修改为:
1
octopress_file = open ( octopress_file_path , 'r' , encoding = 'utf-8' )
解释:因为 octopress_file 已经是UTF-8无BOM编码的文件了,所以读取它的时候,也要将编码方式设为:UTF-8 才行。
搞定
最后贴上当前最新的完整代码(v1.0):https://github.com/AoboJaing/Evernote_Automatic_format_conversion/tree/v1.0
运行结果:
之前创建文件夹folder,现在加一个条件:如果文件夹已经存在,则不用创建
1
2
3
4
5
6
7
8
9
10
11
# 在root_directory路径里面创建一个名为 folder_name 的文件夹。(如果文件夹已经存在,则不用创建)
try :
if os . path . exists ( root_directory + folder_name ) == False :
print ( 'Create a folder:' + root_directory + folder_name )
os . mkdir ( root_directory + folder_name )
pass
else :
print ( 'The folder "' + root_directory + folder_name + '" was already exist. Not need to create again.' )
except OSError as err :
print ( 'File error: ' + str ( err ))
pass
自动检测这个博客是:仅仅一个文件(.md),还是一个文件夹(就是检测这个博文里面有没有图片)
参考博客:Learning Python 025 字符串分割
Demo 程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# -*- coding: utf-8 -*-
path = r'D:\WorkSpace\test_ws\Git(GitHub) 002 如何在GitHub For Windows 软件上为代码库创建一个版本标签 — Ongoing — 2016年12月1日 星期四\Git(GitHub) 002 如何在GitHub For Windows 软件上为代码库创建一个版本标签 — Ongoing — 2016年12月1日 星期四.md'
path2 = r'D:\WorkSpace\test_ws\Git(GitHub) 002 如何在GitHub For Windows 软件上为代码库创建一个版本标签 — Ongoing — 2016年12月1日 星期四.md'
l1 = path . split ( ' \\ ' )
# l1 = path2.split('\\')
# print(l1)
# print(l1[-1])
print ( l1 [ - 2 ])
l2 = l1 [ - 1 ] . split ( '.' )
# print(l2)
print ( l2 [ 0 ])
same = l1 [ - 2 ] == l2 [ 0 ]
print ( same )
运行输出:
1
2
3
Git ( GitHub ) 002 如何在 GitHub For Windows 软件上为代码库创建一个版本标签 — Ongoing — 2016 年 12 月 1 日 星期四
Git ( GitHub ) 002 如何在 GitHub For Windows 软件上为代码库创建一个版本标签 — Ongoing — 2016 年 12 月 1 日 星期四
True
给定马克飞象笔记文件(.md文件)路径,自动获取root_directory路径
Demo 程序:
1
2
3
4
5
6
7
8
9
10
11
12
# -!- coding: utf-8 -!-
path = r'D:\WorkSpace\test_ws\Git(GitHub) 002 如何在GitHub For Windows 软件上为代码库创建一个版本标签 — Ongoing — 2016年12月1日 星期四\Git(GitHub) 002 如何在GitHub For Windows 软件上为代码库创建一个版本标签 — Ongoing — 2016年12月1日 星期四.md'
delimiter = ' \\ '
evernote_is_folder = True
a = - 1
if evernote_is_folder :
a =- 2
mylist = path . split ( delimiter )
print ( delimiter . join ( mylist [: a ]))
自动检测这个博客是:仅仅一个文件(.md),还是一个文件夹 和 给定马克飞象笔记文件(.md文件)路径,自动获取root_directory路径 和 evernote_folder_name名字 的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 自动检测这个博客是:仅仅一个文件(`.md`),还是一个文件夹
# 给定马克飞象笔记文件(`.md`文件)路径,自动获取`root_directory`路径 和 `evernote_folder_name`名字
evernote_file_path = r'D:\WorkSpace\test_ws\Git(GitHub) 002 如何在GitHub For Windows 软件上为代码库创建一个版本标签 — Ongoing — 2016年12月1日 星期四\Git(GitHub) 002 如何在GitHub For Windows 软件上为代码库创建一个版本标签 — Ongoing — 2016年12月1日 星期四.md'
delimiter = ' \\ '
l1 = evernote_file_path . split ( delimiter )
# print(l1[-2])
l2 = l1 [ - 1 ] . split ( '.' )
# print(l2[0])
evernote_is_folder = l1 [ - 2 ] == l2 [ 0 ]
a = - 1
str_temp = '文件'
if evernote_is_folder :
a =- 2
str_temp = '文件夹'
pass
print ( '当前处理的这个马克飞象笔记是一个' + str_temp )
# 马克飞象笔记的文件名
evernote_folder_name = l2 [ 0 ]
# 马克飞象笔记文件夹所在路径
root_directory = delimiter . join ( l1 [: a ]) + ' \\ '
print ( evernote_folder_name )
print ( root_directory )
pass
如果马克飞象笔记只是一个文件,我们就不进行创建文件夹、复制图片和文件内图片链接的修改的操作
很简单,我们只需要在创建文件夹和复制图片的操作的代码执行前加一个条件。满足条件就执行。
1
if evernote_is_folder : # 执行以下代码的前提是:马克飞象笔记是一个文件夹
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 在root_directory路径里面创建一个名为 folder_name 的文件夹。(如果文件夹已经存在,则不用创建)
if evernote_is_folder : # 执行以下代码的前提是:马克飞象笔记是一个文件夹
folder_name_exists = os . path . exists ( root_directory + folder_name )
try :
if folder_name_exists == False :
print ( 'Create a folder:' + root_directory + folder_name )
os . mkdir ( root_directory + folder_name )
pass
else :
print ( 'The folder "' + root_directory + folder_name + '" was already exist. Not need to create again.' )
except OSError as err :
print ( 'File error: ' + str ( err ))
pass
pass
# 将马克飞象笔记文件夹里面的所有图片全部复制到刚刚新创建的folder_name 文件夹(路径)里面
if evernote_is_folder : # 执行以下代码的前提是:马克飞象笔记是一个文件夹
copy_img_command = 'copy "' + root_directory + evernote_folder_name + r'\*.png" "' + root_directory + folder_name + r'\"'
# print(copy_img_command)
os . system ( copy_img_command )
pass
1
2
3
4
5
6
7
8
9
10
11
12
# 将里面的图片链接替换为**Octopress**本地链接的形式
if evernote_is_folder : # 执行以下代码的前提是:马克飞象笔记是一个文件夹
image_local_path = re . findall ( '!\[Alt text\]\((.*?)\)' , evernote_data , re . S )
# print(image_local_path)
image_relative_path = []
for i in range ( len ( image_local_path )):
image_relative_path . append ( '/images/' + folder_name + image_local_path [ i ][ 1 :])
# print(image_relative_path[i])
evernote_data = evernote_data . replace ( image_local_path [ i ], image_relative_path [ i ])
pass
# print(evernote_data)
pass
当前完整的代码在这里:https://github.com/AoboJaing/Evernote_Automatic_format_conversion/tree/v1.1
将整个evernoteToOctopressBlog.py封装成一个类:EvernoteToOctopressBlog
参考网站:Learning Python 023 类编程
当前完整的代码在这里(v2.0):https://github.com/AoboJaing/Evernote_Automatic_format_conversion/blob/v2.0/script/evernoteToOctopressBlog.py
将evernoteToOctopressBlog.py文件写成一个工具(命令行工具),可以向里面传入命令行参数
参考网站:Learning Python 028 获取命令行参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
import optparse
def main ():
# 输入信息:folder_name、 evernote_file_path、octopress_title、octopress_categories、octopress_tags
parser = optparse . OptionParser ( 'usage%prog ' + \
'-f <folder_name> -p <evernote_file_path> -T <octopress_title> -c <octopress_categories> -t <octopress_tags>' )
parser . add_option ( '-f' , dest = 'folder_name' , type = 'string' , \
help = 'be converted Octopress blog file and images file name' )
parser . add_option ( '-p' , dest = 'evernote_file_path' , type = 'string' , \
help = 'evernote file path' )
parser . add_option ( '-T' , dest = 'octopress_title' , type = 'string' , \
help = 'be converted Octopress blog \' s title' )
parser . add_option ( '-c' , dest = 'octopress_categories' , type = 'string' , \
help = 'be converted Octopress blog \' s categories' )
parser . add_option ( '-t' , dest = 'octopress_tags' , type = 'string' , \
help = 'be converted Octopress blog \' s tags' )
( options , args ) = parser . parse_args ()
if ( options . folder_name == None ) | ( options . evernote_file_path == None ) | \
( options . octopress_title == None ) | ( options . octopress_categories == None ) | \
( options . octopress_tags == None ):
print ( parser . usage )
exit ( 0 )
pass
else :
folder_name = options . folder_name
evernote_file_path = options . evernote_file_path
octopress_title = options . octopress_title
octopress_categories = options . octopress_categories
octopress_tags = options . octopress_tags
# print(folder_name)
# print(evernote_file_path)
# print(octopress_title)
# print(octopress_categories)
# print(octopress_tags)
eTo = EvernoteToOctopressBlog ( folder_name , evernote_file_path , octopress_title , octopress_categories , octopress_tags )
eTo . autoProcess ()
pass
pass
if __name__ == '__main__' :
main ()
pass
运行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
D : \WorkSpace \python_ws \Evernote_Automatic_format_conversion > python script \evernoteToOctopressBlog . py - h
Usage : usageevernoteToOctopressBlog . py - f < folder_name > - p < evernote_file_path > - T < octopress_title > - c < octopress_categories > - t < octopress_tags >
Options :
- h , -- help show this help message and exit
- f FOLDER_NAME be converted Octopress blog file and images file name
- p EVERNOTE_FILE_PATH
evernote file path
- T OCTOPRESS_TITLE be converted Octopress blog 's title
- c OCTOPRESS_CATEGORIES
be converted Octopress blog 's categories
- t OCTOPRESS_TAGS be converted Octopress blog 's tags
D : \WorkSpace \python_ws \Evernote_Automatic_format_conversion >
运行:(成功)
1
2
3
4
D : \WorkSpace \python_ws \Evernote_Automatic_format_conversion > python script \evernoteToOctopressBlog . py - f "2016-12-1-python-get-command-line-arguments" - p "D:\WorkSpace \t est_ws\Learning Python 028 获取命令行参数 — Over — 2016年12月1日 星期 四.md" - T "Learning Python 028 获取命令行参数" - c "python" - t "python3, python2, 命令行, 参数, args"
当前处理的这个马克飞象笔记是一个文件
D : \WorkSpace \python_ws \Evernote_Automatic_format_conversion >
现在最新的代码在这里:https://github.com/AoboJaing/Evernote_Automatic_format_conversion/blob/v3.0/script/evernoteToOctopressBlog.py
基本完成了
可以收工了!
— 2016-12-2 03:24:59
需要升级的地方
检查folder_name 字符串是否有非法字符和字符串的长度是否超过最大允许长度
参考网站:
Python 文件夹及文件操作(特全,特别详细)
http://www.cnblogs.com/feeland/p/4463682.html
2017年2月20日 星期一 发现一个bug:当我将图片链接写成:
2017-2-20 22:45:07 我想将这个bug记录下来。
现在,修改这个bug。修改思路:
我们需要修改这段代码:
1
2
3
def replaceImgLink ( self , evernote_data ):
# 将里面的图片链接替换为**Octopress**本地链接的形式
image_local_path = re . findall ( '!\[Alt text\]\((.*?)\)' , evernote_data , re . S )
我们在这里,将这里使用一次正则表达式,改为使用两次正则表达式。:
大概的伪码的样子是:
1
image_local_path = re . findall ( '!\[Alt text\]\((.*?)\)' , evernote_data , re . S )
第一步里面我们的正则表达式的匹配模板(!\[Alt text(.*?))是一个前面有字符串,而后面没有字符串的一个字符串。那么这个时候,如果你想要程序正常的运行,你需要在这个匹配模板里面(.*?)后面添加上:\Z,用来表示后面没有字符串。(对着正则表达式的这个知识点,你可以参考这篇博客 ,这里对正则表达式的这个知识点有详细的介绍。)
修改为:
1
2
3
4
5
6
image_local_path = re . findall ( '!\[Alt text(.*?)\)' , evernote_data , re . S )
for i in range ( len ( image_local_path )):
image_local_path_this = image_local_path [ i ]
image_local_path_step2 = re . findall ( ']\((.*?)\Z' , image_local_path_this , re . S )
image_local_path [ i ] = image_local_path_step2 [ 0 ]
pass
现在修改后的代码:依然在GitHub里面 。
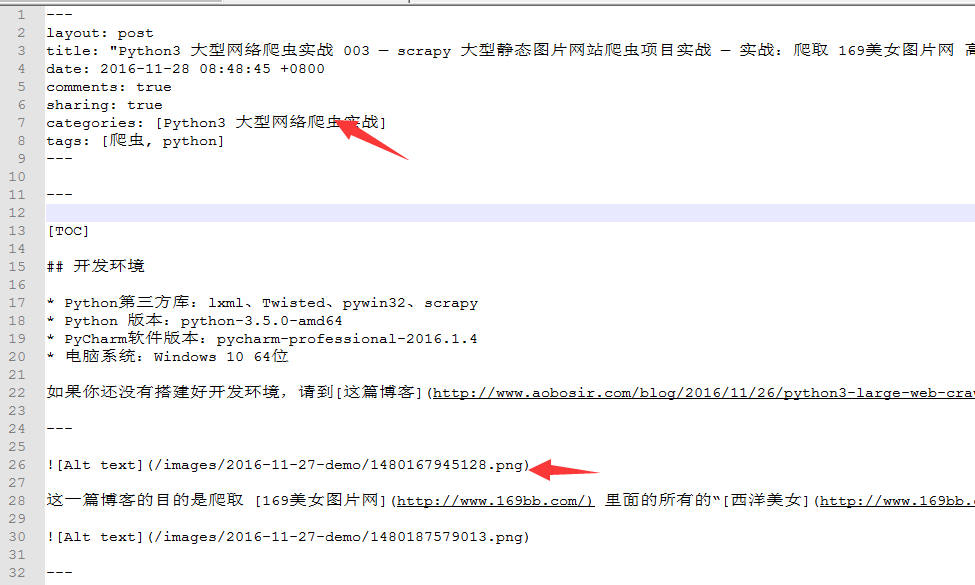


 的时候,程序不会识别到这是一个图片链接
的时候,程序不会识别到这是一个图片链接