开发环境
- Python第三方库:lxml、Twisted、pywin32、scrapy
- Python 版本:python-3.5.0-amd64
- PyCharm软件版本:pycharm-professional-2016.1.4
- 电脑系统:Windows 10 64位
如果你还没有搭建好开发环境,请到这篇博客。
当我在使用正则表达式去提取网页源代码中的有效数据的时候。发现:我要提取的有效数据所需要使用的正则表达式中有换行。那么这个时候,正则表达式要怎么写?
目标网站:http://blog.csdn.net/github_35160620/article/details/53512977
要提取的有效信息:访问的数量
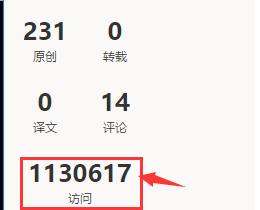
查看网页源代码:

所以,如果我们想提取出访问数量,需要使用的正则表达式中会存在换行:
1
2
| '''<dt class="item">(.^?)</dt>
<dd class="item_name">访问'''
|
但是这样是不能匹配到结果。而正确的正则表达式是下面这样的:
1
| '<dt class="item">(.*?)</dt>\r\n <dd class="item_name">访问'
|
使用转义字符 \r\n 来表示换行。
代码:
1
2
3
4
5
6
7
8
9
10
| def next(self, response):
pattam_visits = '<dt class="item">(.*?)</dt>\r\n <dd class="item_name">访问'
# print('response.body type is ', type(response.body))
# print('response.body.decode type is ', type(response.body.decode('utf-8', 'ignore')))
body_data = response.body.decode('utf-8', 'ignore') # .replace(u'\xa9', u'')
visits = re.compile(pattam_visits).findall(body_data)[0]
print('当前访问量为:', visits)
print('-------------------')
pass
|
compile() 函数的使用方法在这里可以了解。