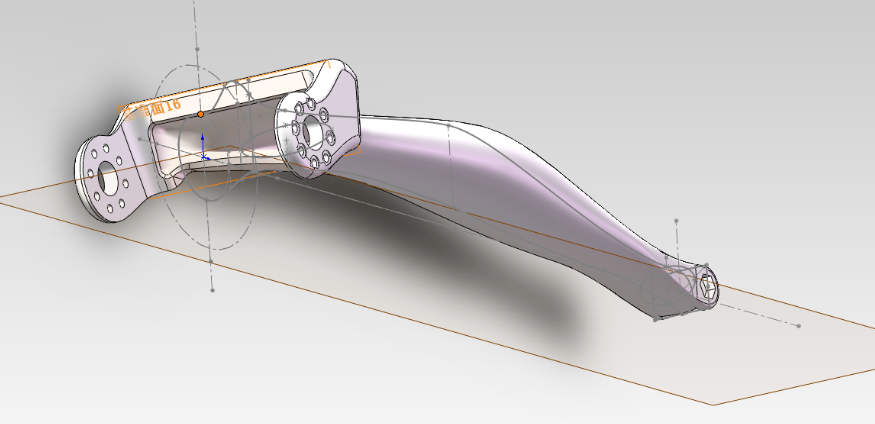
如果你在装配体里面插入一个装配体的话,如果被插入的装配体原本是有可动关节的,但是被插入后,可动的关节不能运动了。
要想让它还能动, 其他很简单,我们只需要这样做:
对着我们需要恢复可动的关节的转配体:
然后将 求解为 选为 柔性(F)。(被插入到装配体中的装配体默认这一项是为 刚性®的。)
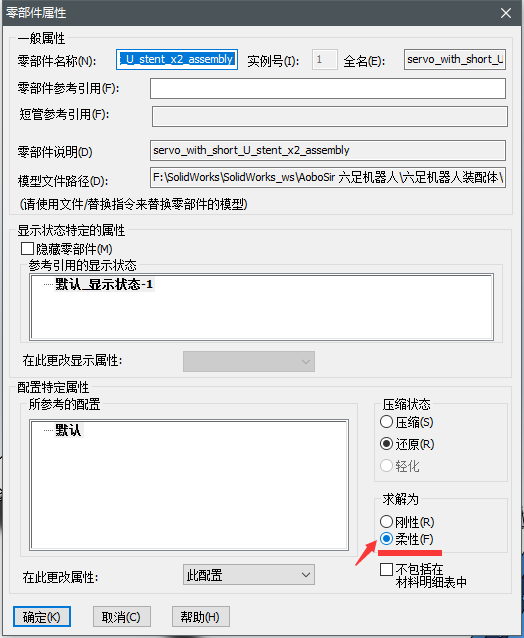
现在转配体里面的包含的装配体的可动关节就可以动了。(如果可动的关节太多,你会明显的感觉到SolidWorks软件运行有点卡。)
如果你在装配体里面插入一个装配体的话,如果被插入的装配体原本是有可动关节的,但是被插入后,可动的关节不能运动了。
要想让它还能动, 其他很简单,我们只需要这样做:
对着我们需要恢复可动的关节的转配体:
然后将 求解为 选为 柔性(F)。(被插入到装配体中的装配体默认这一项是为 刚性®的。)
现在转配体里面的包含的装配体的可动关节就可以动了。(如果可动的关节太多,你会明显的感觉到SolidWorks软件运行有点卡。)
下载网站:http://www.mfcad.com/solidworks/xiazai/18686.html
我们下载两个文件,一个是SolidWorks软件安装包,一个是注册软件(就是破解软件)。
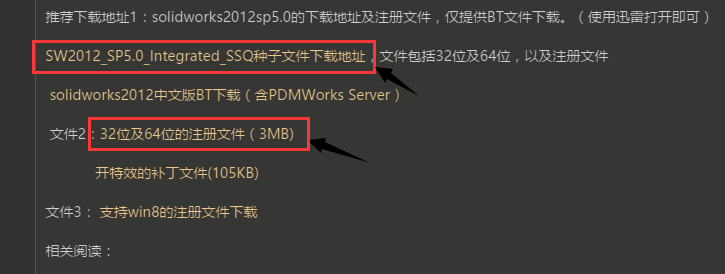
这次下载的是BT文件,你可以使用迅雷软件下载。
下载已经下载好了。
把电脑的网给断了:
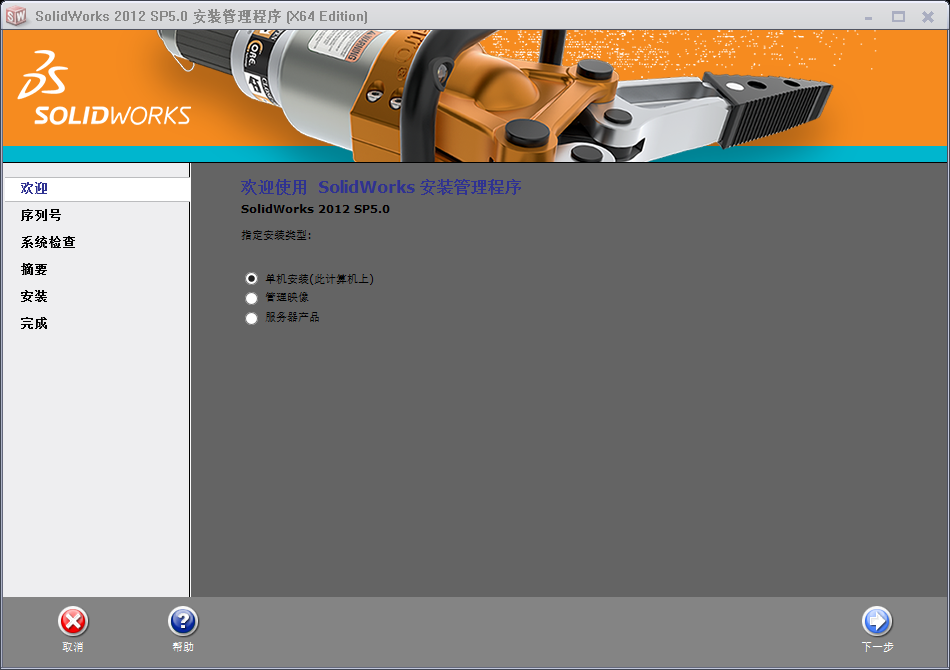
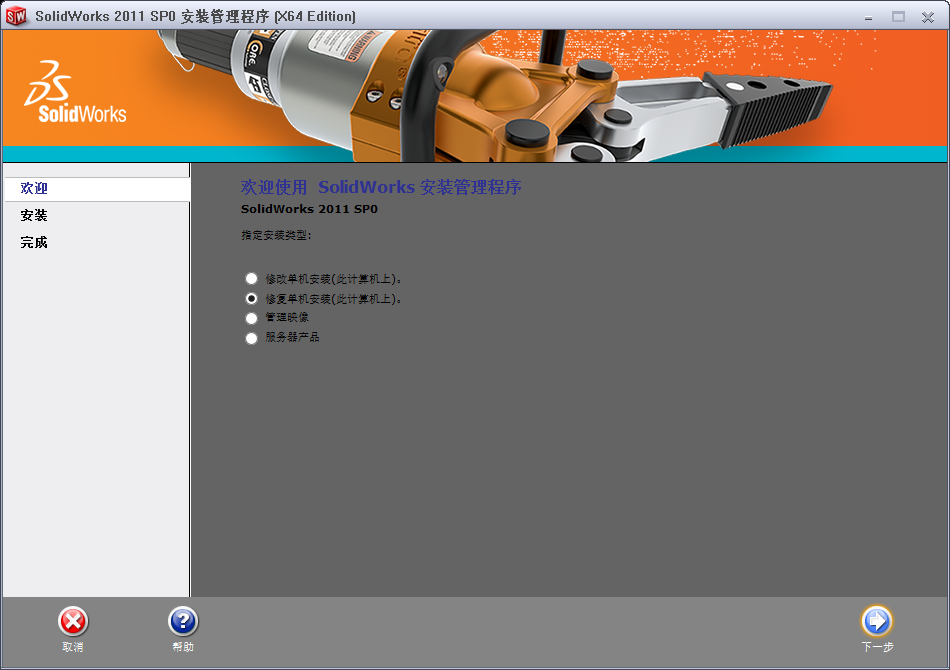
选择 单机安装(此计算机上):
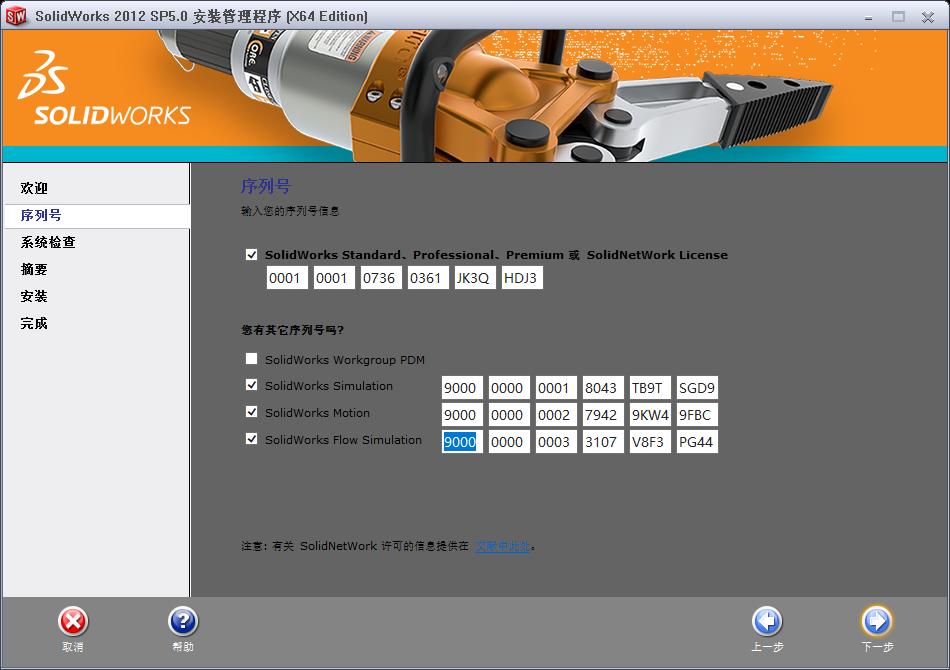
接下来,添加序列号:
附序列号: SolidWorks Serial: 0000 0000 0000 3486 Q5HF FG98 或者 0001 0001 0736 0361 JK3Q HDJ3 其他产品的序列号: SolidWorks Simulation 9000 0000 0001 8043 TB9T SGD9 SolidWorks Motion 9000 0000 0002 7942 9KW4 9FBC Flow Simulation 9000 0000 0003 3107 V8F3 PG44 SW Composer 9000 0000 0021 4754 DCB4 HC3J SW ComposerPlayer 9000 0000 0022 1655 536J H9KH SW Electrical 2D 9000 0000 0000 1616 MDZ8 R8J2 注意,输入序列号以后,最好是先断网,以跳过远程验证。
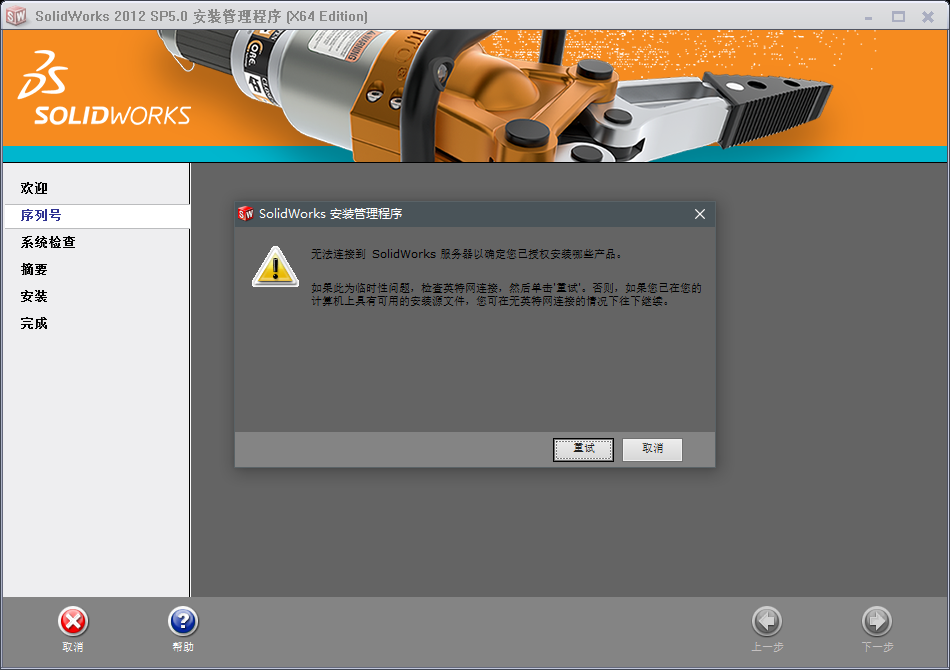
出现了下面的没有网络的提示。我们直接点击 取消 即可:
出现下面的截图,我们需要一个一个的对其进行配置。


我选择安装到 C盘:
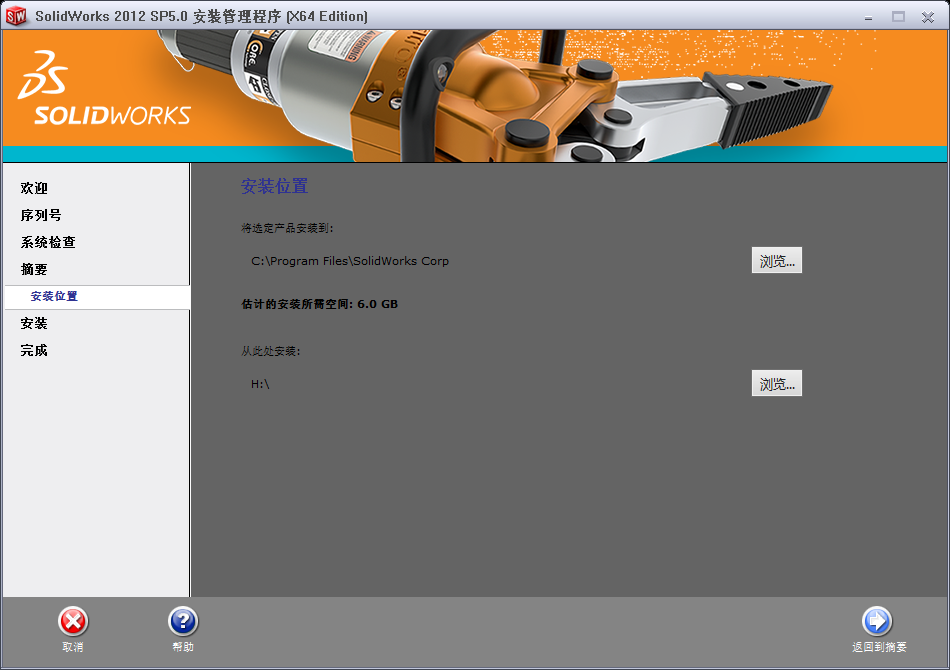

因为我之前安装了SolidWorks 2011软件,然后卸载了它,所以我的电脑里面还是有Toolbox的,所以,我现在现在的单选项:
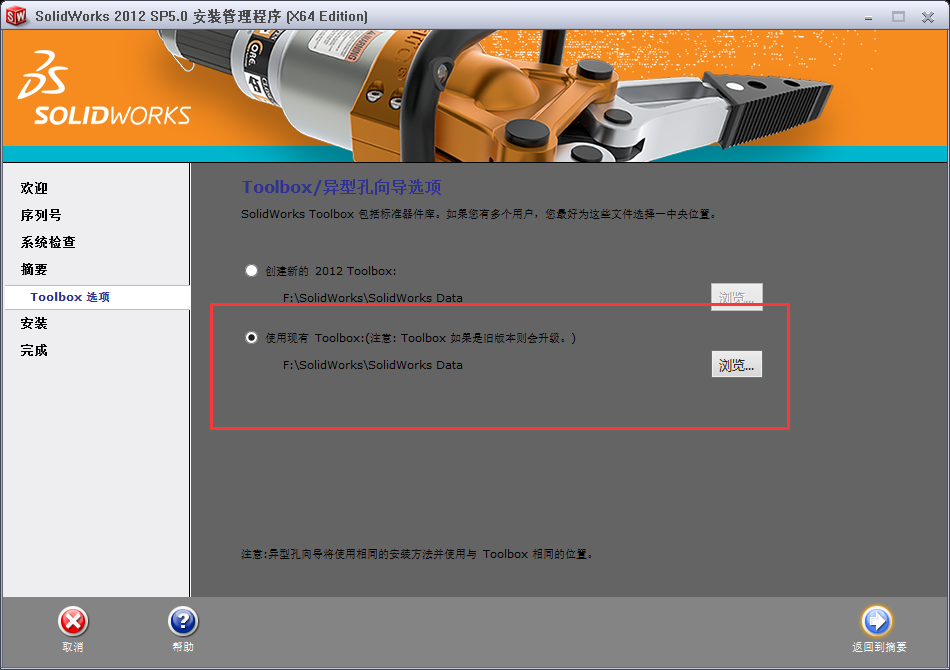
点击 现在安装
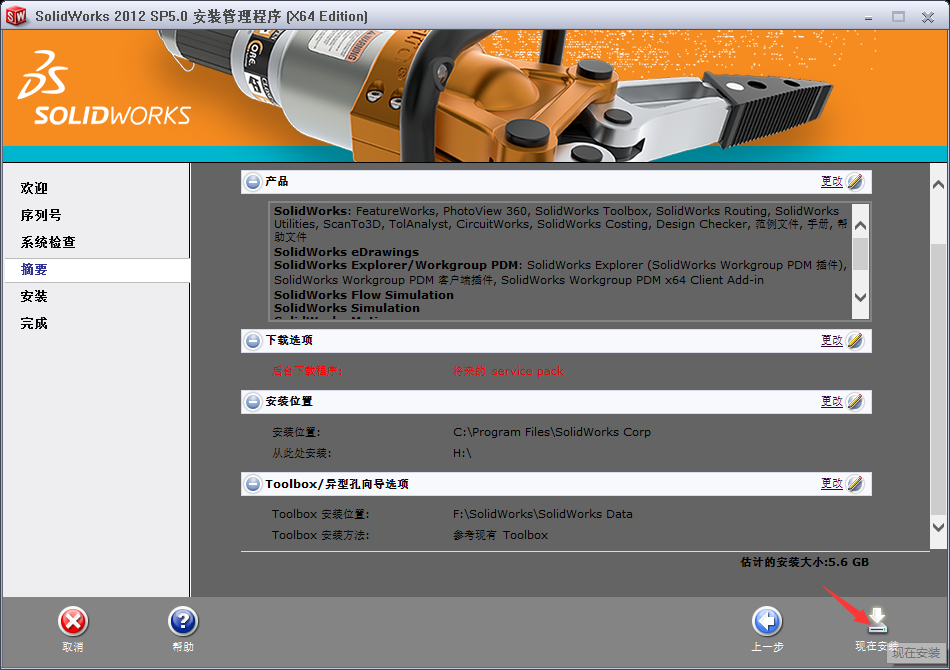
出现下面的提示框。我们直接选择:是
开始安装:
大约10分钟的时间,终于安装完成了:
双击启动SW2010-2013.Activator.SSQ.exe注册机:
出现下面的窗口,我们直接点击 :Install>>
弹出下面的提示窗口。我们直接点击 是
弹出下面的提示窗口,直接点击 是
点击 是
点击 是
弹出下面提示窗口,点击 是:
点击 Finish 按钮
现在就已经破解完了。
http://www.mfcad.com/solidworks/anzhuang/23651.html

弹出下面的窗口,选择是:

成功:

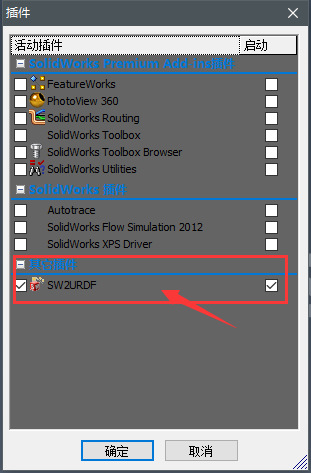
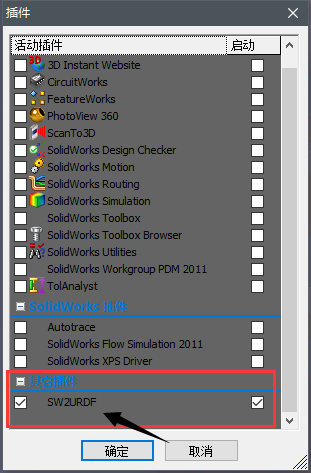
因为,我之前没有已经安装过sw_urdf_exporter插件。并且我没有卸载:

现在,我们在SolidWorks 2012 软件 中看看 这个插件还在不在:

还在:
我们以一个例子来学习如何制作装配体。
装配的概念.zip : 链接:http://pan.baidu.com/s/1skBX41v 密码:kff7
这里有包含一个机器人的所有零件的压缩包,这里面都是单独的零件。
接下来,我们要做的事情就是将这些单独的零件制作成一个装配体。
启动SolidWorks软件,然后先新建一个装配体:
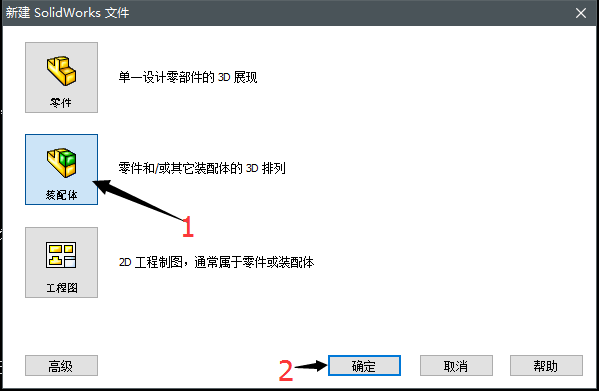
点击 浏览:
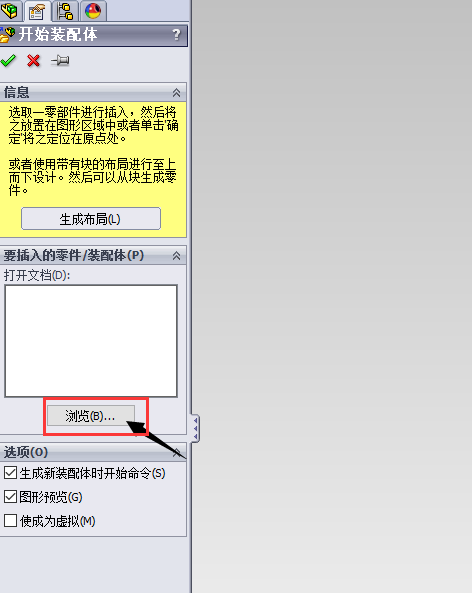
我们先选择其中的RectBase.SLDPRT零件。
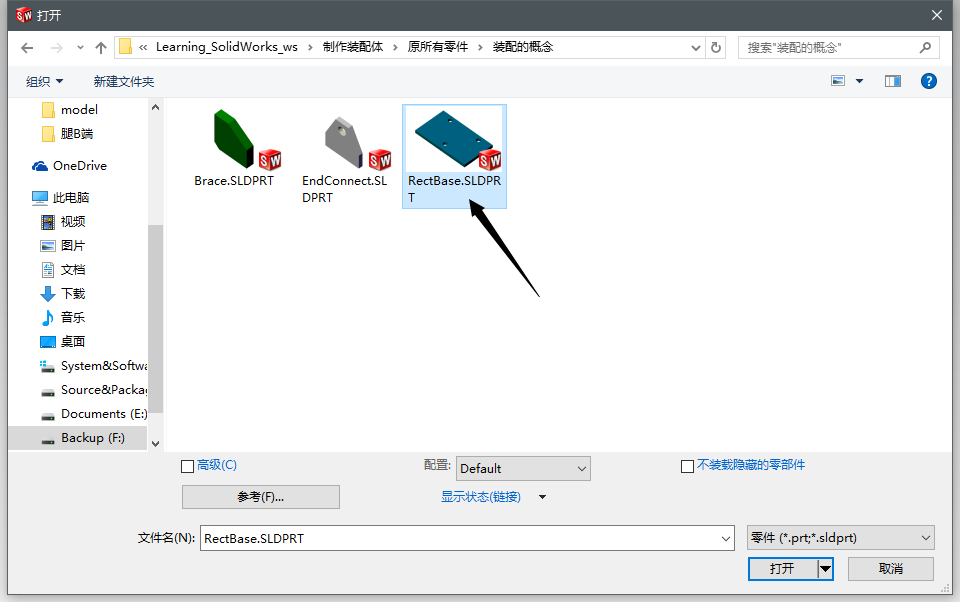
直接点击 确定:
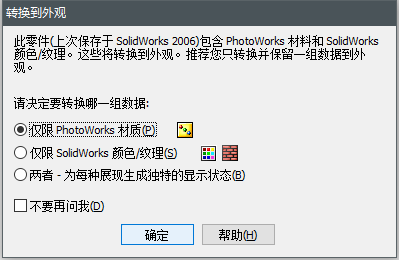
这个时候,鼠标是和零件绑定在一起的,你鼠标移动到哪个位置,零件就到哪个位置。当你鼠标一点击,那么零件就会固定在这个位置上了。这是不行的。(这个时候是关键了)如果你鼠标随便的一点击,零件固定在一个位置,你不知道它被放在了什么位置。你根本就不知道。
正确的做法:
装配体里面有一个默认的原点,就是(0, 0)点,同时零件本身也有一个零点。我们现在需要做的事情是:将这个零件的原点与这个装配体的原点重合。如何重合,很简单:可视化窗口里面不需要点击鼠标,将鼠标移动到设计树这边,我只需要点击 上面对号(就是 确定的意思)。软件会自动帮我们将第一个零件固定。

这样,我们就成功的在装配体中插入了第一个零件。(插入第一个零件的要点就是:必须要将零件的原点与装配件的原点重合。)
接着,我们插入第二个零件。还是一样:
点击 浏览:
对于第二个和第三个零件,我们就可以随便点了。我们只需要在这个可视化界面里面随便点一下。
和插入第二个零件一样的方法,将第三个零件插入到装配件里面。
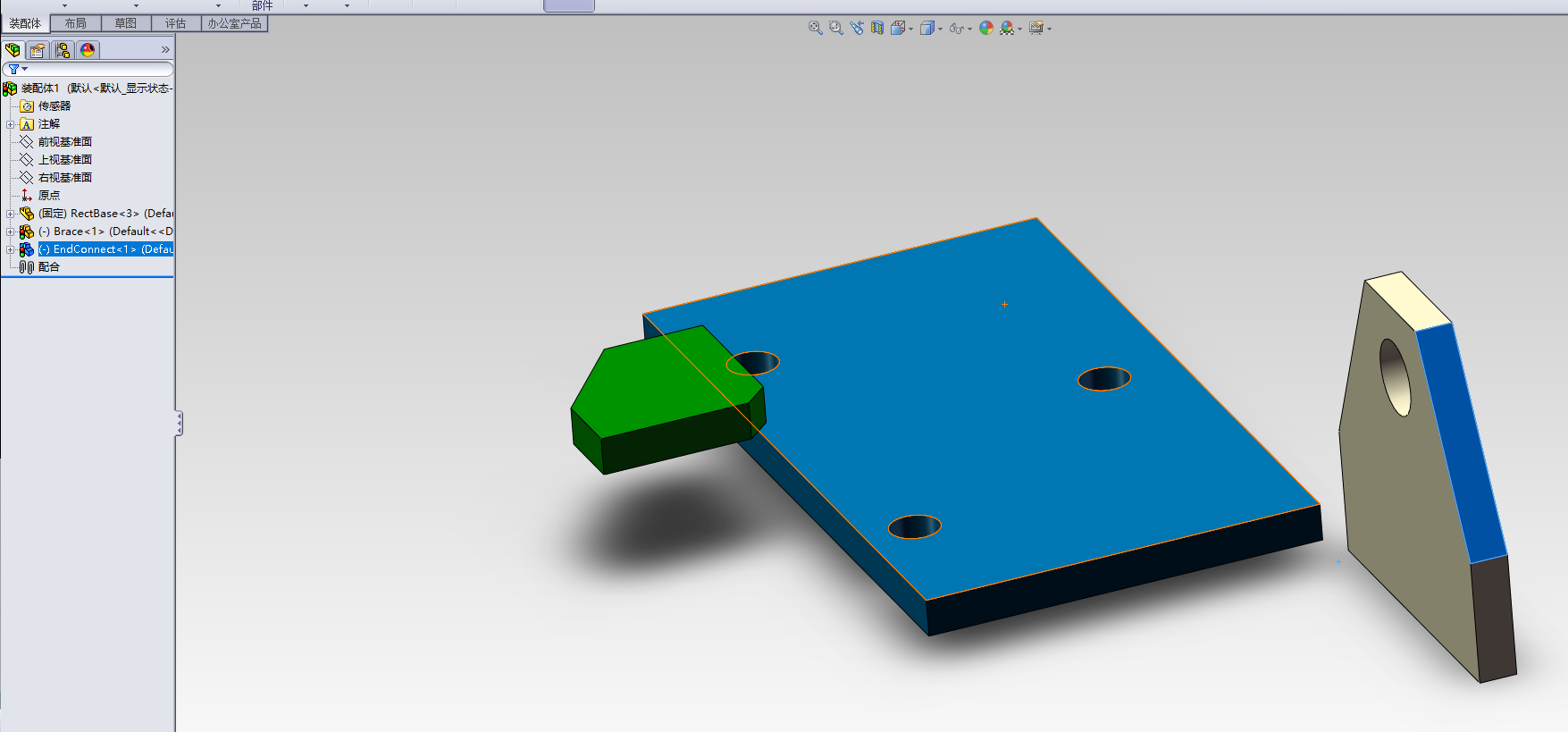
好的,零件都放进来了,现在我们就要开始装配了。
当鼠标选中了一个零件,按住鼠标左键,就是移动这个零件。鼠标的滚轮还是缩放的功能。鼠标中间按住不松口,就是整个视角上的旋转(看不同方式上的视图)。鼠标右键还是一样是选择菜单。如果是使用鼠标右键选中这个零件后,然后鼠标右键按住不动,那么就是真正的对单个零件的旋转。
这就是装配体中,对鼠标的基本操作。现在熟悉了鼠标,现在我们就来开始做装配。
一个零件在空间中有六个自由度,其中三个是平移,三个是旋转。我们要做的事情就是限制这些自由度,自由度限定死了,那么它就在空间中完全固定下来了,就不会随便乱动了。
如果你留一个自由度在那,那么它就是一个会旋转的装配体。所以,简单的说:做装配体就是限制零件在空间中的自由度。(所以做装配体是很简单的。)
现在,我们就来限制这些零件的自由度。
限制零件的自由度,其实就是做配合。
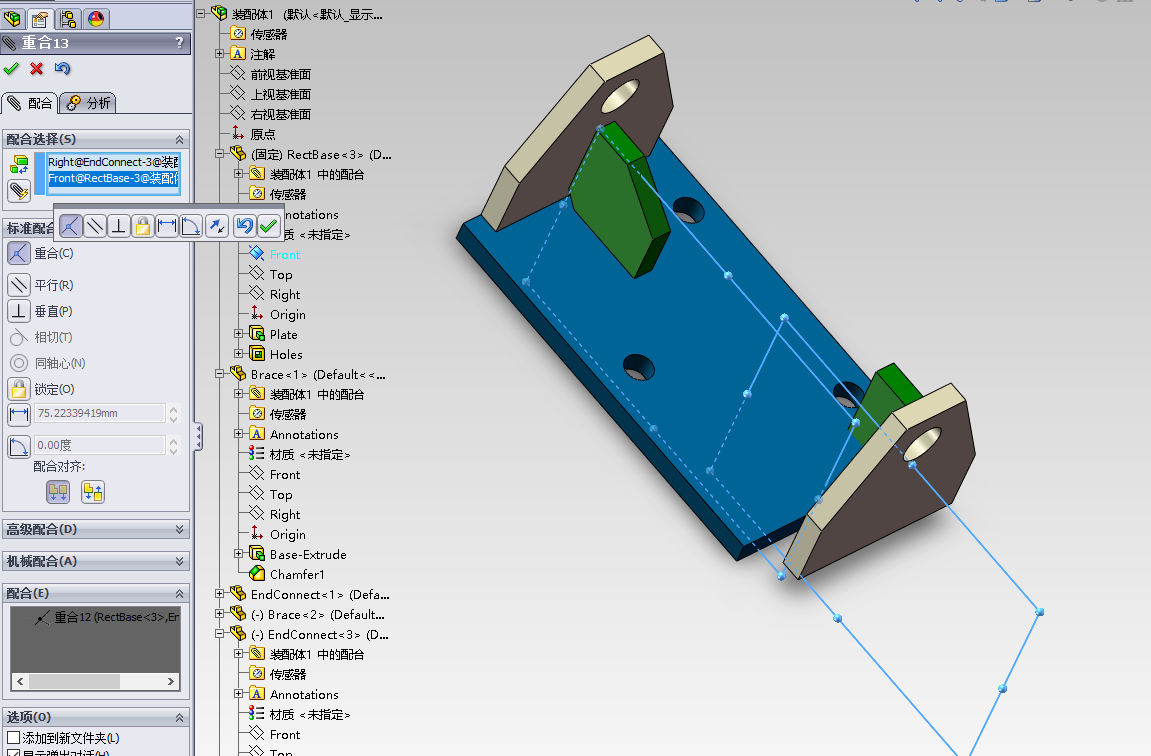
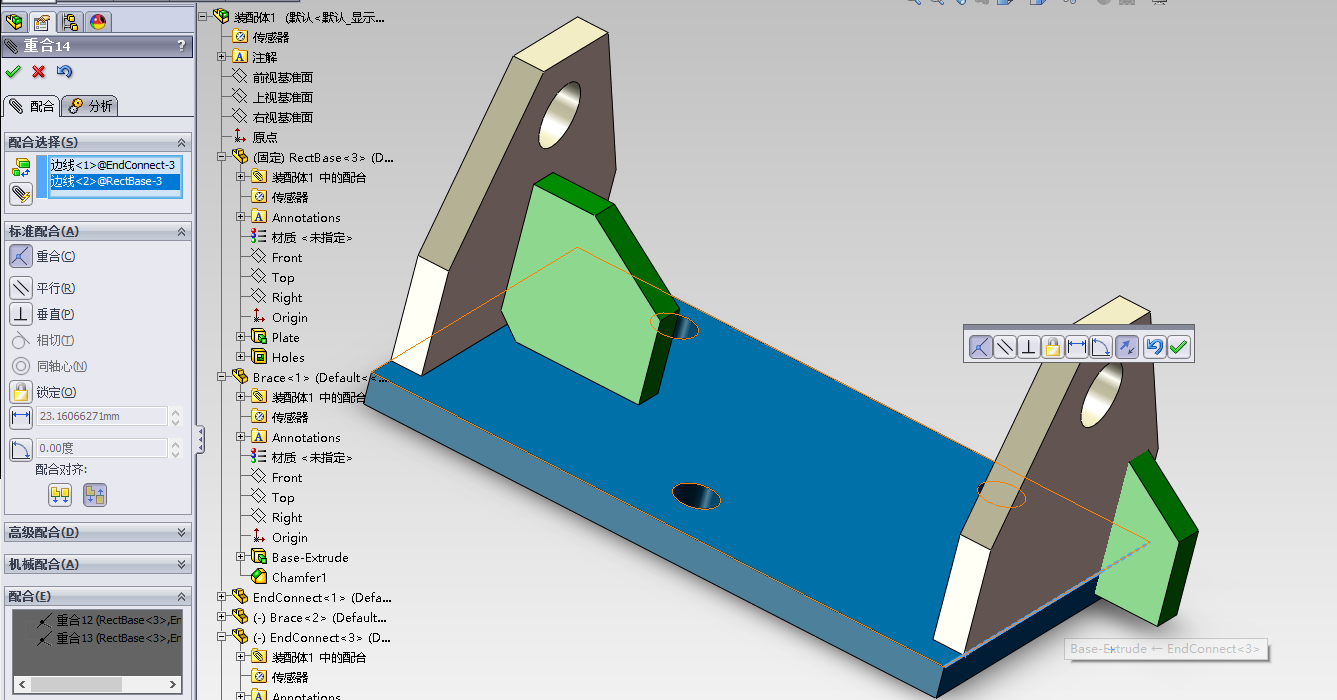
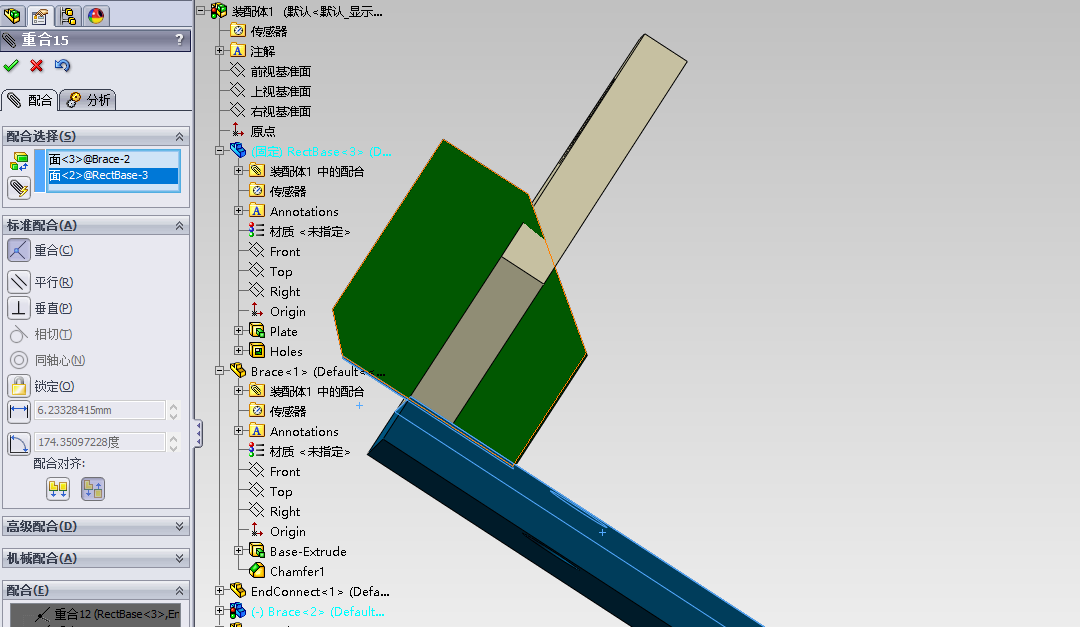
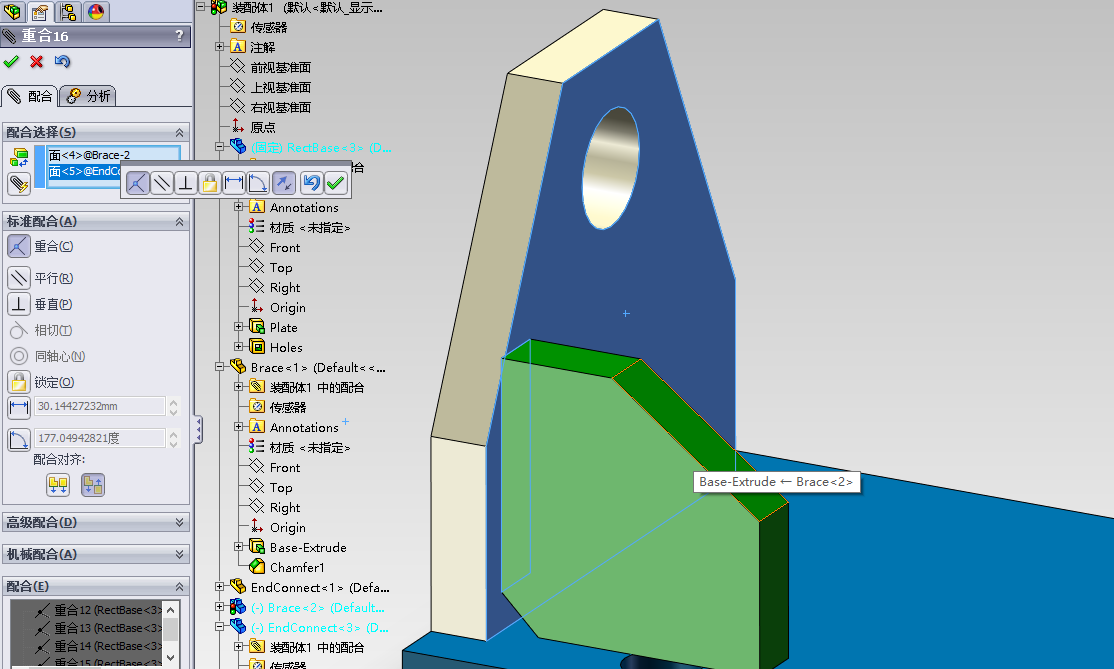
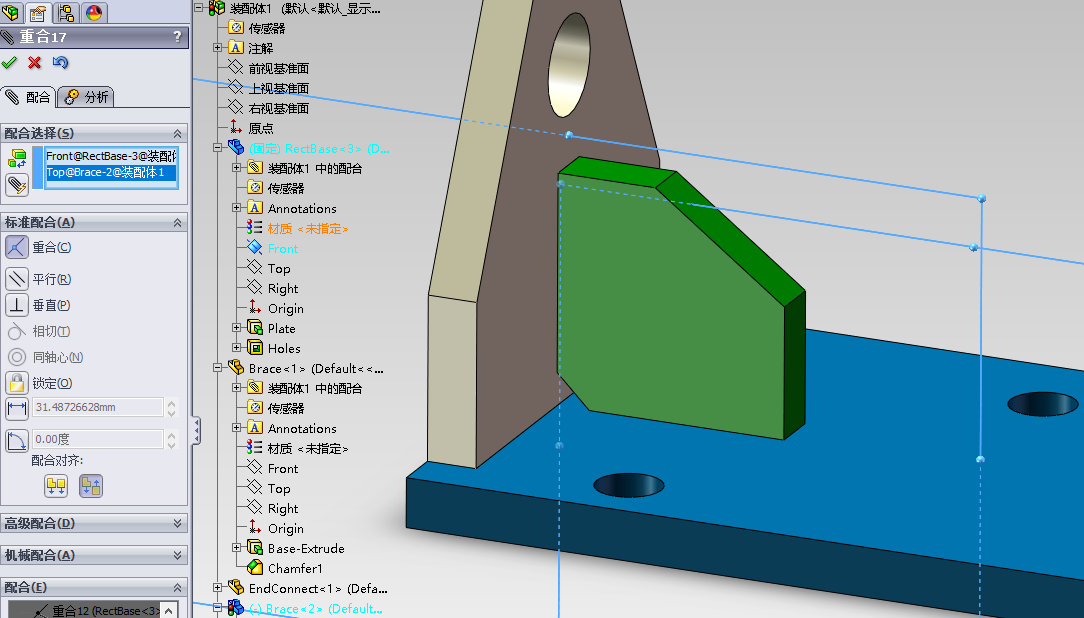
我们现在就做第一个导入的零件和第三个导入的零件进行配合。
先点击 配合 工具 :
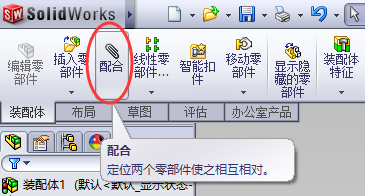
分部选择两个零件的需要重合的面。

配合好了,就可以点击确定了。
配合一般都是进行连续配合。所以,你配合了一次,是不会退出配合命令的,我们还会继续进行接下来的几次配合。
接下来就是使用同样的方法,进行配合了。

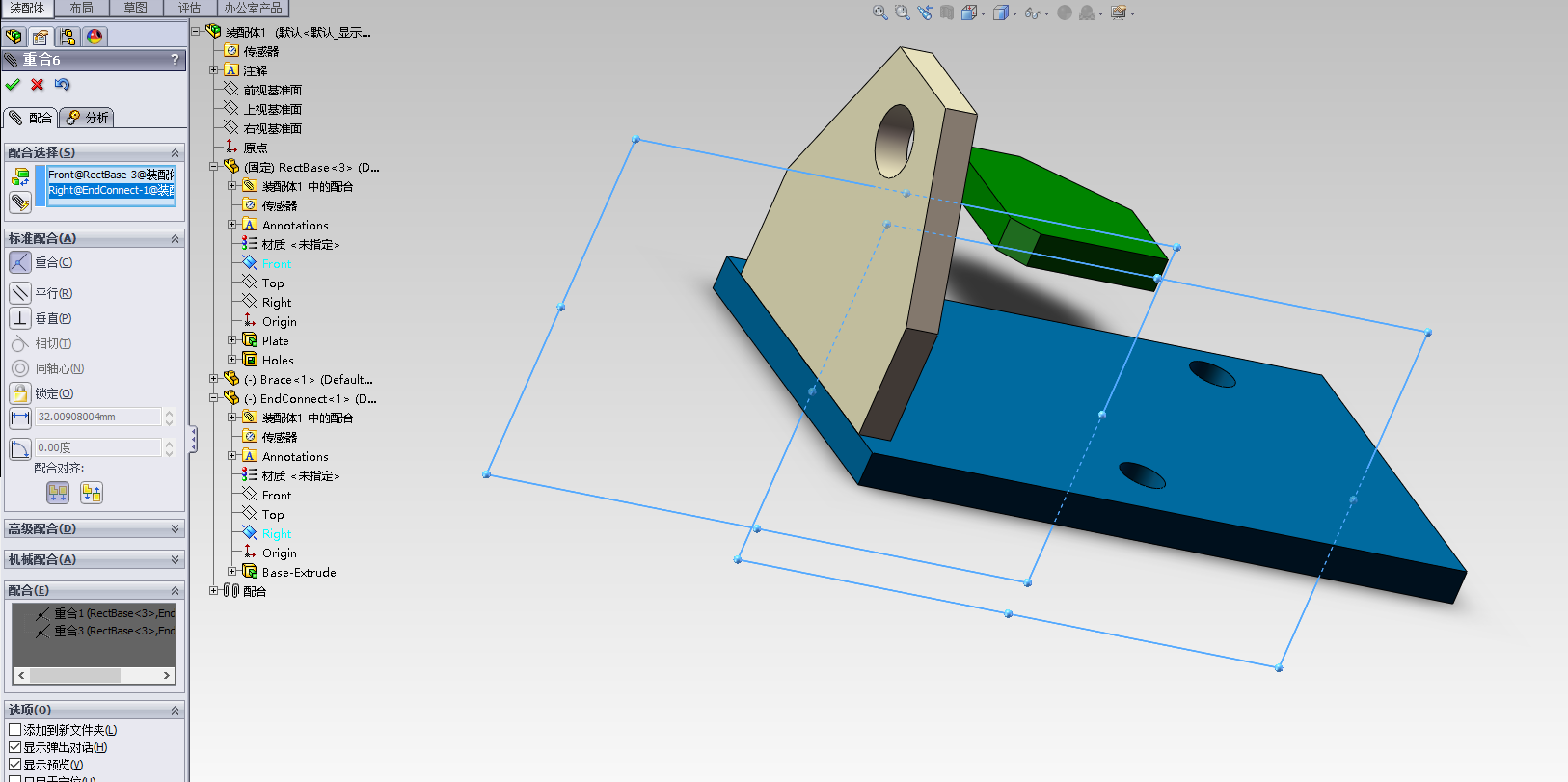
这样,我们就将第一个零件和第二个零件完全的配合了,它们现在已经被完全的定义了。现在点击 确定 图标来退出配合操作。
现在使用同样的道理,现在来装配第二个零部件。
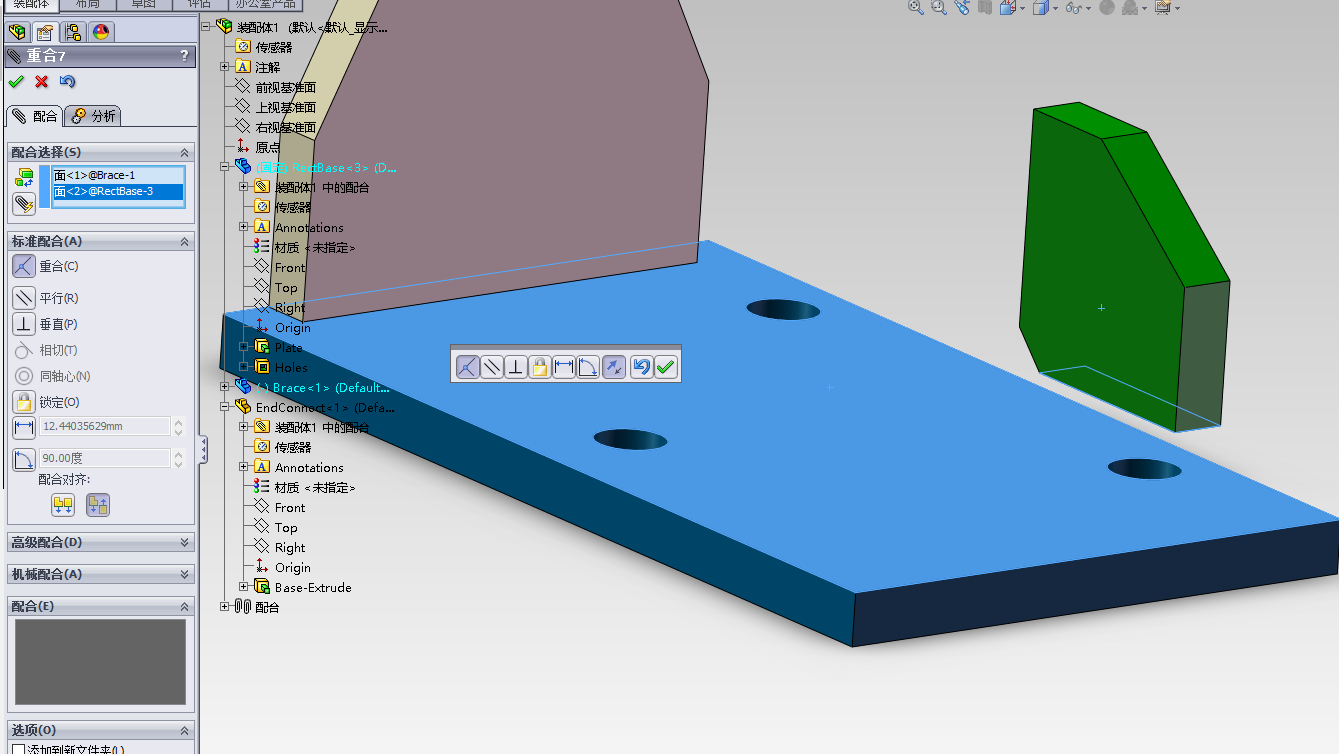
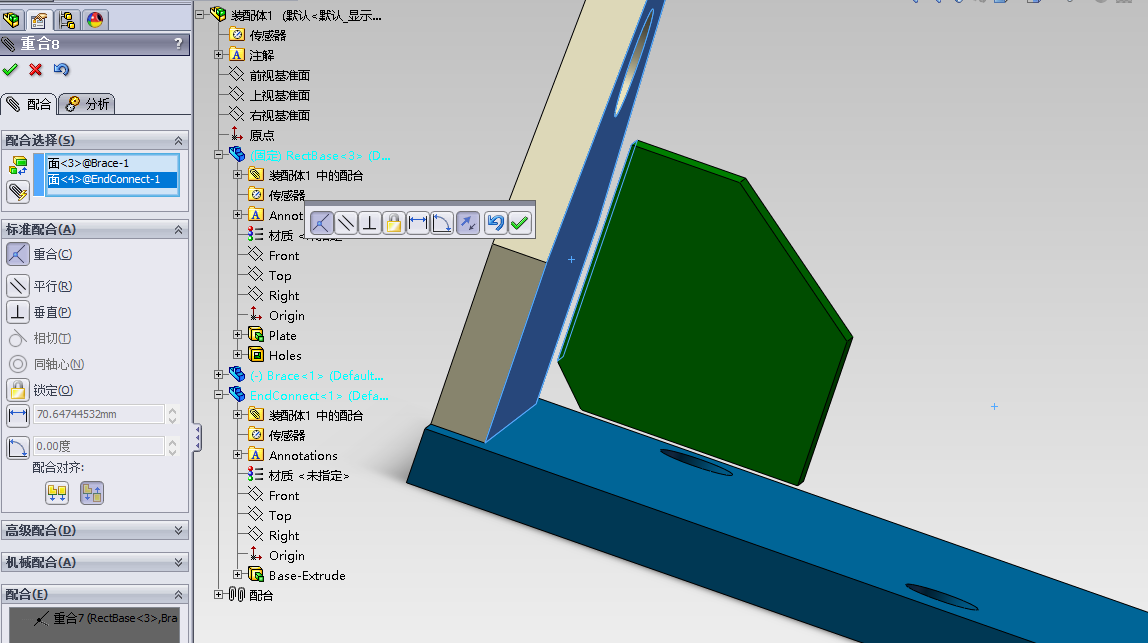
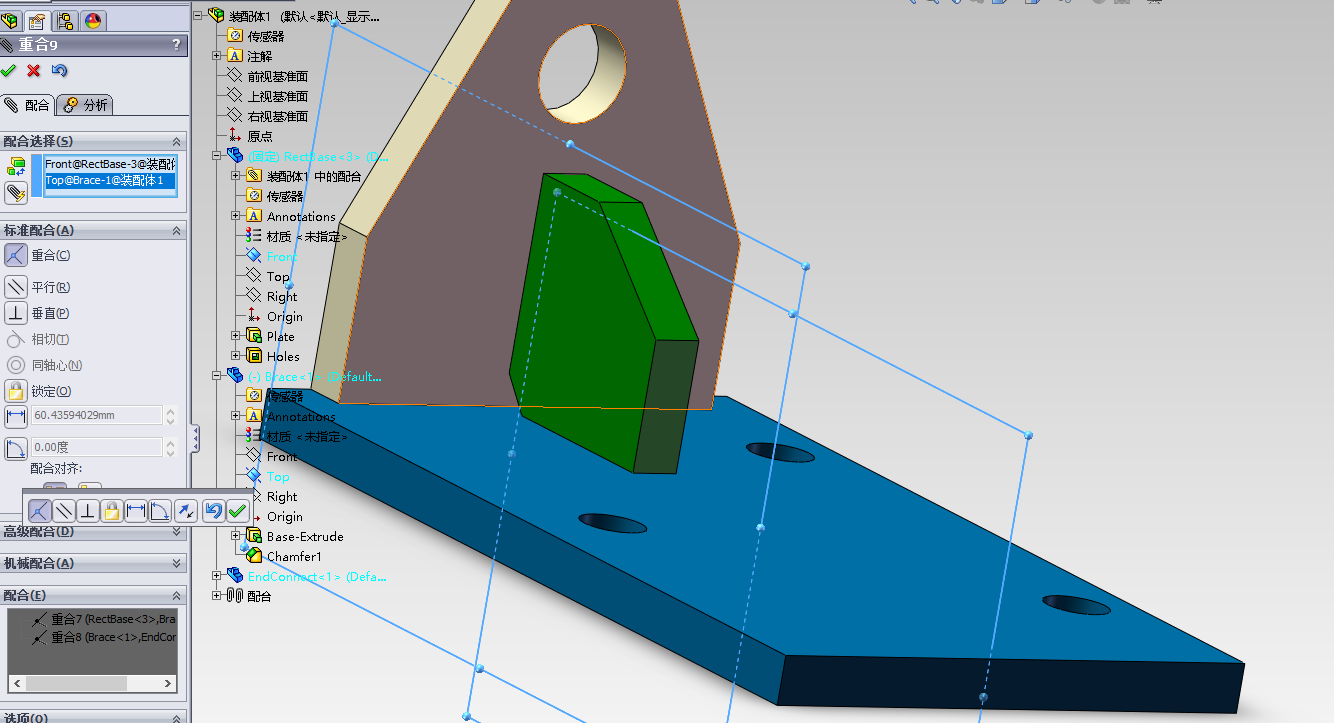
现在,三个零件都装配好了。现在我们就可以点击 确定 按钮来退出配合操作。
在装配体里面,千万不要选择镜像。镜像会出现一个什么样的效果:镜像会产生一个新的零部件。这跟我们在零部件的状态下生成镜像是一样的。
那么我现在要做装配件的另外一面,我要怎么做:就是复制这个零件。
按住 Ctrl 键,然后鼠标左键不要松开,推动这跟零件,这样就复制出来了。复制完之后,松开 Ctrl 键完成复制。
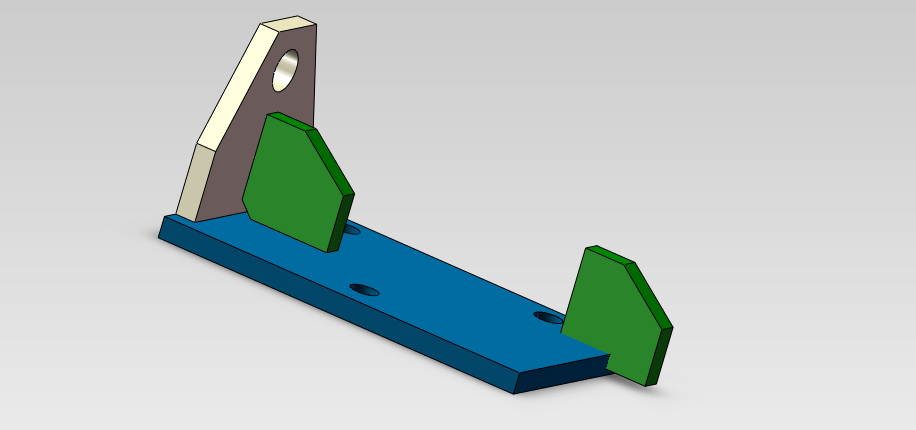
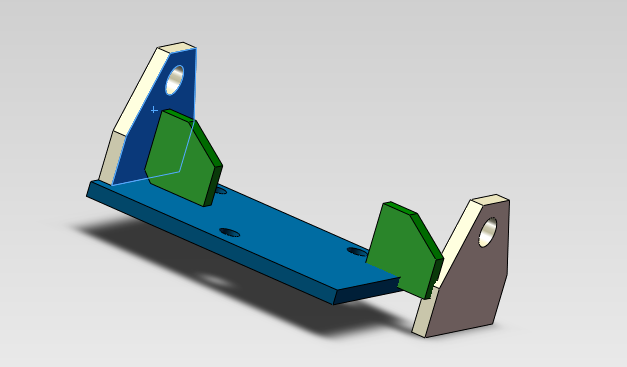
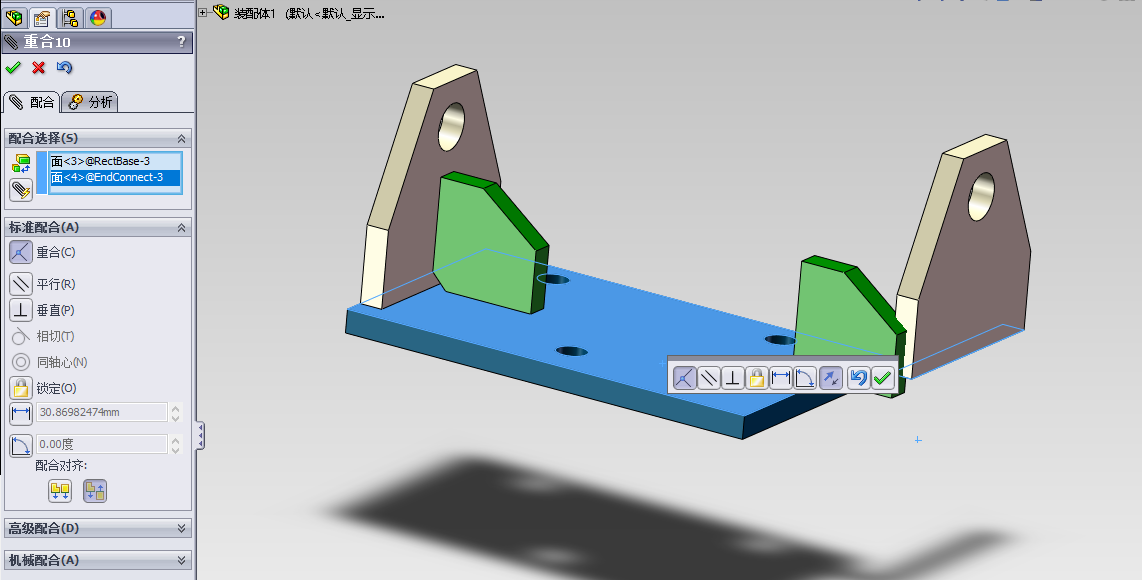
然后,我们在使用上面同样的操作,再对复制出来的零部件进行同样操作,将其装配到装配体上。
今天,我将需要打印的文件考到了3D打印机的SD卡里面,3D打印机还通过USB线连接着电脑的USB口。我这个时候将一个读卡器插到了电脑上,这个时候一件悲哀的事情发生了:已经打印了一半的3D打印机不打印了(停机了)。
我现在终于知道了为什么之前会有莫名其妙的打印停止。
我得到的经验:在3D打印的时候,不要将3D打印机的USB线与电脑连接。让3D打印机离线脱机运行。这样就不会受到电脑端的影响。
1 2 | |
参考网站:http://answers.ros.org/question/212492/catkin_make-command-not-found/
先来查看当前ROS的环境变量:
1
| |
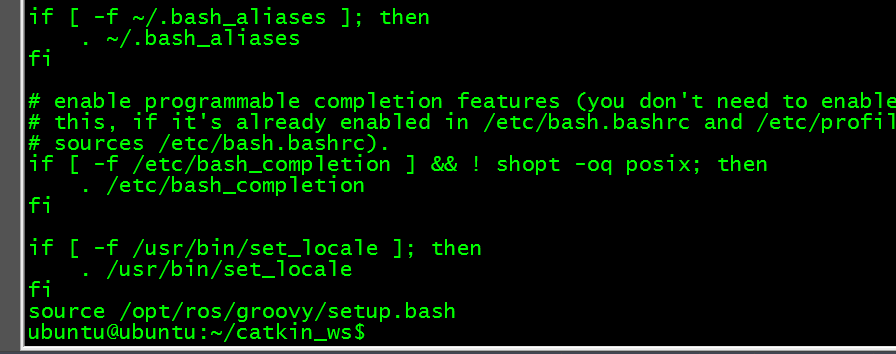
我们发现里面已经有source /opt/ros/indigo/setup.bash这行代码了。(如果没有一定要添加上。)
为什么还是出现问题呢。
后来我才发现,出现错误的原因:
是因为我输错catin_make
正确的命令是:
1
| |
注意: 1 . ROS 提高篇这个专栏的教学有门槛。 2 . 如果你没有学习前面的教程,请想学习前面的 beginner_Tutorials 和 learning_tf 的ROS 相关教程。 3 . 你还需要会使用SolidWorks软件。这里有相关的博文。
参考网站:SolidWorks to URDF Exporter
sw_urdf_exporter它使用一个SolidWorks软件的一个插件,这个插件是ROS团队设计的。sw_urdf_exporter这个插件的官方介绍网站在这里。
下面来简单的介绍一下这个插件:这个插件的功能是将SolidWorks里面的模型导出成URDF格式的文件,也就是说,我们其实可以管这个插件叫做:SolidWorks里面的URDF文件的导出器。这个导出器将会创建一个类似ROS的包,其中包的路径里面包含模型的网络(Mesh)、纹理(Texture)和机器人模型文件(URDF)文件。对于当个的SolidWorks模型文件,导出程序将在URDF文件里面创建单个链接;对于SolidWorks的装配件,导出程序江湖构建链接,然后在基于SolidWorks组件层次创建结构树,导出程序中的输出器可以自动确定正确的关节类型、关节变换和轴(joint type, joint transforms and axes)。
到这个网站里面,直接点击下面这个按钮:
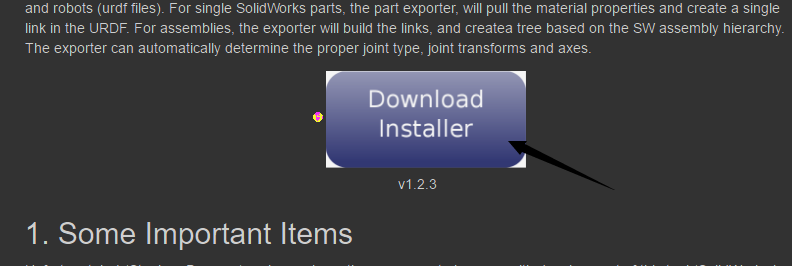
当弹出一个网页,点击里面的 View raw,就可以下载了:
下载后,双击运行。(我现在先不急着运行,我们先说说使用这个软件的注意事项,然后在手把手的给你介绍如何给SolidWorks软件安装这个插件。)
安装需要注意的事情:
你不能将其安装到标有SW2URDF的目录。否则运行程序会抛出未处理的异常错误。
同时,因为这个插件是使用C#编写的,所以,如果你的电脑里面安装.NET Framework V4,或者没有升级到.NET Framework V4以上,你需要先安装这个。
上面的两个注意事项的知道了后,我们现在就来安装。双击刚刚下载的安装包。
其实你也可以直接下载源代码,然后在使用Visual Studio 软件来手动编译生成可执行文件。
sw_urdf_exporter项目的源代码在这里下载:
下载需要使用
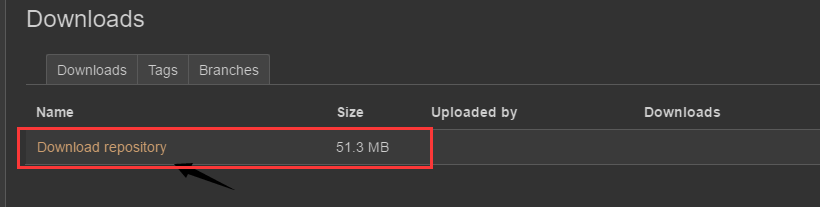
hg或者ssh命令来下载,git工具时不能下载Bitbucket这个网站里面的源代码的,又因为我的Windows系统电脑里面只安装了git工具,所以下面我介绍的下载方法是:直接下载源代码。点击 Download 标签:
然后直接点击 Download repository 就下载了。
下载好了,解压,里面有sw_urdf_exporter项目的源代码,以及一些示例模型(SolidWorks模型)。
(我们这里是使用安装包进行安装。)双击安装包,它会自动的识别到你电脑里面当前安装了SolidWorks软件的路径。我们直接 Next。
点击 Intall
秒速完成。点击 Finish
好的,现在已经安装完成了。现在启动SolidWorks软件:
选择: 插件…
你会在 其他插件 里面看到一项 SW2URDF,正确情况是被勾选的,如果没有被勾选,请勾选。
现在就已经想这个插件安装成功了。下面我们就来测试一下这个插件如何使用。
对于这个插件,ROS官方给出了专门的教程,在这里。
接下来,下一个博文,我们就来介绍,这个插件如何使用。
[TOC]
开发环境:
folder_name = '2016-11-27-demo'evernote_folder_name)同一路径(root_directory)下,创建一个文件夹,取名为folder_name变量evernote_folder_name)里面的所有图片全部复制到刚刚新创建的folder_name 文件夹(路径)里面。evernote_folder_name)里面的笔记文件(.md文件),复制一份放到root_directory路径下,并将其名字重命名为:folder_name变量,并将其后缀修改为:.markdownfolder_name.markdown 文件,将里面的图片链接替换为Octopress本地链接的形式# xxx) 和 笔记本(@(xxx))(方法:以后记马克飞象笔记,第1行是标题,第3行是 归宿笔记本。所以,我们只需要简单的将前3行删除就可。)folder,现在加一个条件:如果文件夹已经存在,则不用创建.md),还是一个文件夹(就是检测这个博文里面有没有图片).md文件)路径,自动获取root_directory路径.md),还是一个文件夹 和 给定马克飞象笔记文件(.md文件)路径,自动获取root_directory路径 和 evernote_folder_name名字 的代码如下:evernoteToOctopressBlog.py封装成一个类:EvernoteToOctopressBlogevernoteToOctopressBlog.py文件写成一个工具(命令行工具),可以向里面传入命令行参数这样,程序的功能就都完成了。
参考网站:
1 2 3 4 5 6 7 8 | |
注意:如果想要创建的文件夹是已经存在的,那么执行上面的程序会出现下面的错误:
FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。
所以这段代码容易出现错误:如果文件夹已存在或者文件夹名中有不允许使用的字符时,os.mkdir()函数都会执行失败。所以,这段代码需要进行异常处理:
参考网站:Python 异常处理
1 2 3 4 | |
这样,在运行程序的时候就不会再出现错误了。但是当你给定的文件名中有非法字符时,创建文件夹是不会成功的,但是程序不会报错。
参考网站:
将马克飞象笔记文件夹里面的所有图片全部复制到刚刚新创建的folder_name 文件夹(路径)里面。
python自带的第三方库:shutil 可以实现文件的复制操作,但是它只能一次复制一个文件。所以我们不使用这个shutil模块来做复制文件的操作。
我们使用python调用Windows系统DOS命令行里面的copy工具来继续文件的复制。
下面的代码可以将马克飞象笔记文件夹里面的所有图片复制到folder_name文件夹里面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
其实,代码中的 os.system(copy_img_command) 这段代码就是等价于:在 DOS 窗口执行:copy "D:\WorkSpace\test_ws\\Python3 大型网络爬虫实战 003 — scrapy 大型静态图片网站爬虫项目实战 — 实战:爬取 169美女图片网 高清图片 — Over — 2016年11月26日 星期六\*.png" "D:\WorkSpace\test_ws\\2016-11-27-demo\" 这个指令。
1 . 在DOS 里面,执行下面的命令,有的是对的,有的是错的:
1 2 3 4 5 6 7 8 | |
总结:
\是一个特殊字符,它不能再字符串中正常的显示,如果必须显示,就这样写:\\\,不能使用/ 和 // ,使用这两个都是错的,都会导致 DOS找不到指定的文件路径\ ,你写成 \\ 或者 \\\ 或者 \\\\\\ … 对是可以正常执行的,不会出现错误。2 . 同时,我发现:
python 的字符串前面加上r,说明这个字符串是raw string,即无需转义的字符串,意思就是这个字符串里面有什么就是什么。
但是我发现了python的一个bug:
1 2 3 | |
1 2 3 4 | |
1 2 3 4 | |
1 2 3 | |
参考网站:
1 2 3 4 5 | |
使用正则表达式先提取出原来的图片链接。再将这个链接修改为Octopress本地形式的链接。最后进行替换。
1 2 3 4 5 6 7 8 | |
# xxx) 和 笔记本(@(xxx))我是这样设计的,我们今后写马克笔记定一个规则:
以后记马克飞象笔记,第1行是标题,第3行是 归宿笔记本。所以,我们只需要简单的将前3行删除就可。
参考网站:
1 2 3 4 5 6 7 8 9 | |
运行:
1 2 3 4 5 6 7 8 9 10 11 | |
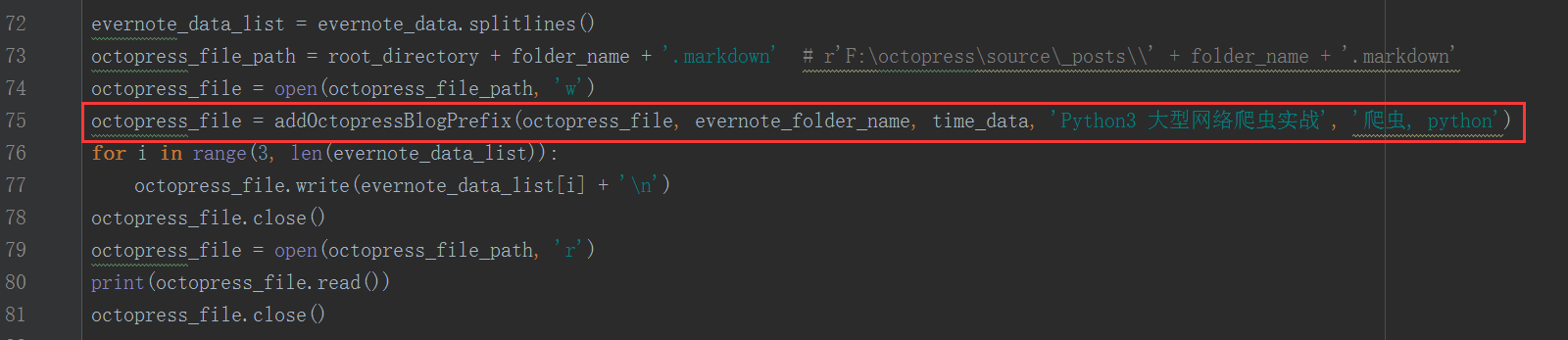
使用这个addOctopressBlogPrefix()函数:
这个系统时间是这样得到的:(参考网站)
1 2 3 4 | |
如果现在将这个文件和图片转移到Octopress站点路径里面,然后执行rake generate命令会出现下面这个错误:
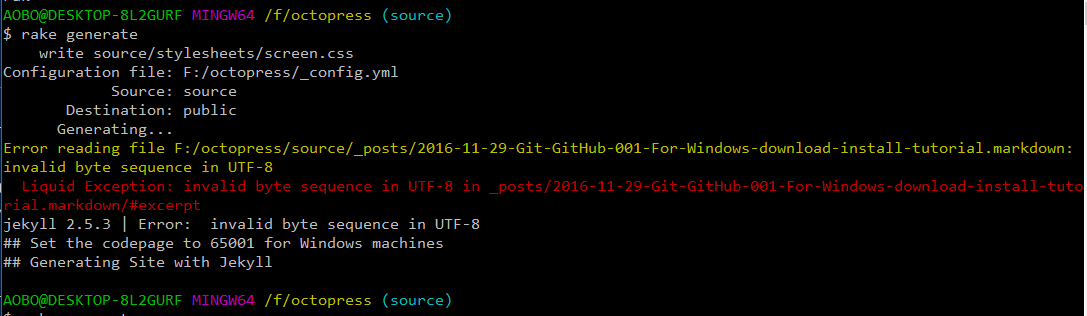
1 2 | |
这个错误时说:这个文件xxxx.markdown它的编码不是标准的UTF-8无BOM编码方式编辑的文件。
所以,为了解决这个问题,我们需要将输出的Octopress博文文件(.markdown后缀文件)在保存的时候将其转换为以Utf-8无BOM编码方式编码的文件。
其实很简单,我们只需要将下面这行代码:
1
| |
修改为:
1
| |
这样octopress_file文件就是以Utf-8无BOM编码方式编码的文件。
我们也看到了,其实不是将
octopress_file保存为以Utf-8无BOM编码方式编码的文件,而是创建这个一个以Utf-8无BOM编码方式编码的文件octopress_file。
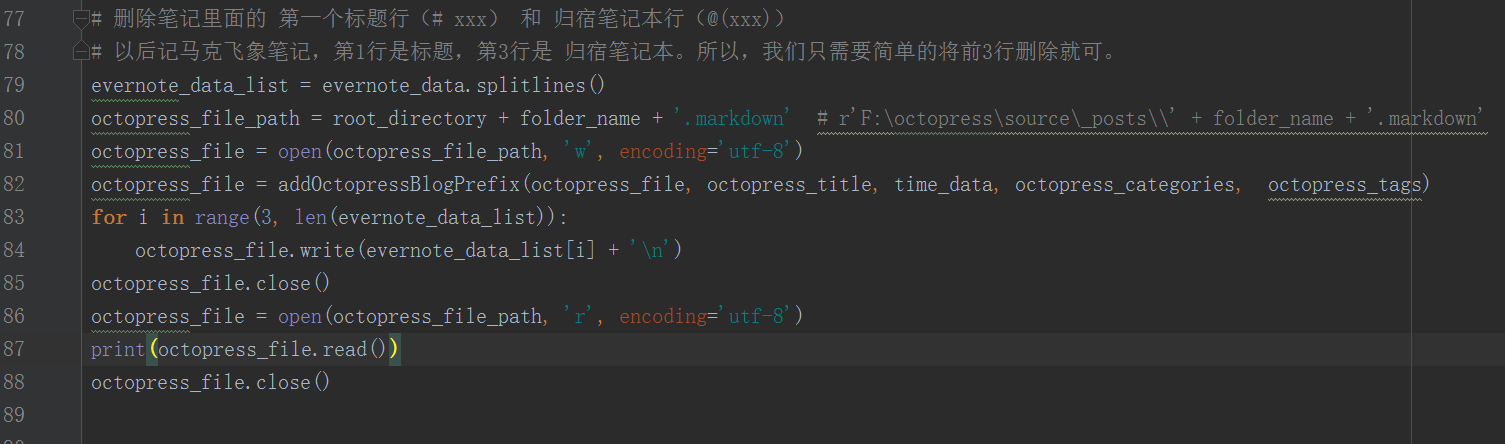
虽然已经成功的将最终得到的Octopress博文文件(.markdown后缀文件)保存为UTF-8无BOM编码文件。但是在执行 print(octopress_file.read()) 这句代码的时候,出现了UnicodeDecodeError 错误,如下。

1 2 | |
哦,这个问题也非常容易解决,可以说现在不在是一个难问题了。
解决办法:将print(octopress_file.read())这行代码的上一行:
1
| |
修改为:
1
| |
解释:因为 octopress_file 已经是UTF-8无BOM编码的文件了,所以读取它的时候,也要将编码方式设为:UTF-8 才行。
最后贴上当前最新的完整代码(v1.0):https://github.com/AoboJaing/Evernote_Automatic_format_conversion/tree/v1.0
运行结果:

folder,现在加一个条件:如果文件夹已经存在,则不用创建1 2 3 4 5 6 7 8 9 10 11 | |
.md),还是一个文件夹(就是检测这个博文里面有没有图片)参考博客:Learning Python 025 字符串分割
Demo 程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
运行输出:
1 2 3 | |
.md文件)路径,自动获取root_directory路径Demo 程序:
1 2 3 4 5 6 7 8 9 10 11 12 | |
.md),还是一个文件夹 和 给定马克飞象笔记文件(.md文件)路径,自动获取root_directory路径 和 evernote_folder_name名字 的代码如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
很简单,我们只需要在创建文件夹和复制图片的操作的代码执行前加一个条件。满足条件就执行。
1
| |
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
当前完整的代码在这里:https://github.com/AoboJaing/Evernote_Automatic_format_conversion/tree/v1.1
evernoteToOctopressBlog.py封装成一个类:EvernoteToOctopressBlog当前完整的代码在这里(v2.0):https://github.com/AoboJaing/Evernote_Automatic_format_conversion/blob/v2.0/script/evernoteToOctopressBlog.py
evernoteToOctopressBlog.py文件写成一个工具(命令行工具),可以向里面传入命令行参数参考网站:Learning Python 028 获取命令行参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | |
运行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
运行:(成功)
1 2 3 4 | |
可以收工了!
— 2016-12-2 03:24:59
folder_name 字符串是否有非法字符和字符串的长度是否超过最大允许长度参考网站:
Python 文件夹及文件操作(特全,特别详细) http://www.cnblogs.com/feeland/p/4463682.html
 的时候,程序不会识别到这是一个图片链接
的时候,程序不会识别到这是一个图片链接2017-2-20 22:45:07 我想将这个bug记录下来。
现在,修改这个bug。修改思路:
我们需要修改这段代码:
1 2 3 | |

我们在这里,将这里使用一次正则表达式,改为使用两次正则表达式。:
大概的伪码的样子是:
1
| |
第一步里面我们的正则表达式的匹配模板(!\[Alt text(.*?))是一个前面有字符串,而后面没有字符串的一个字符串。那么这个时候,如果你想要程序正常的运行,你需要在这个匹配模板里面(.*?)后面添加上:\Z,用来表示后面没有字符串。(对着正则表达式的这个知识点,你可以参考这篇博客,这里对正则表达式的这个知识点有详细的介绍。)
修改为:
1 2 3 4 5 6 | |
现在修改后的代码:依然在GitHub里面。
如果你还没有搭建好开发环境,请到这篇博客。
例子程序在这里:learning_python_08_06.py
参考网站:python正则表达式详解

当我们的匹配字符串的末尾处没有字符串的时候,我们使用\Z来表示结束处。
同样的道理:当我们的匹配字符串的开头处没有字符串的时候,我们使用
\A来表示开头处。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
这个demo程序中,使用了两层正则表达式。
第一层的匹配字符串是:!\[Alt text(.*?)\)。它可以得到](./1485164492501.png这样或者| 240x0](./1485166756931.png这样的结果。
解决我们将得到的结果再进行一次正则表示匹配。这次使用的匹配字符串是:]\((.*?)\Z。通过这次匹配,得到的结果就都是图片的地址了。(想这样:./1485181859693.png)
注意:在匹配字符串中的
(和)需要使用转义字符\修饰。
先画好一些草图,并准备一个实体。
实体,我已经画好了:
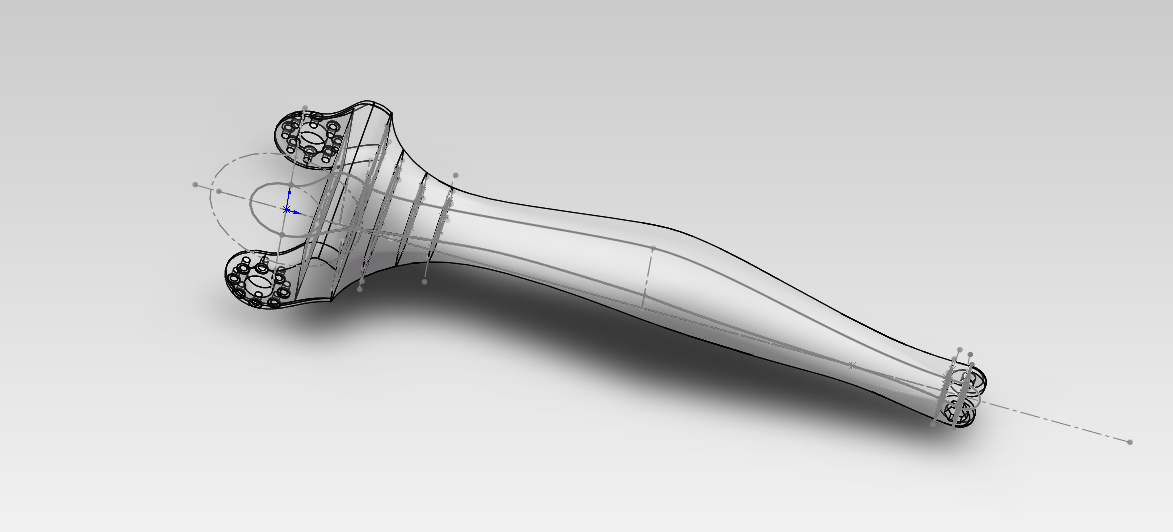
基准面我也画好了:
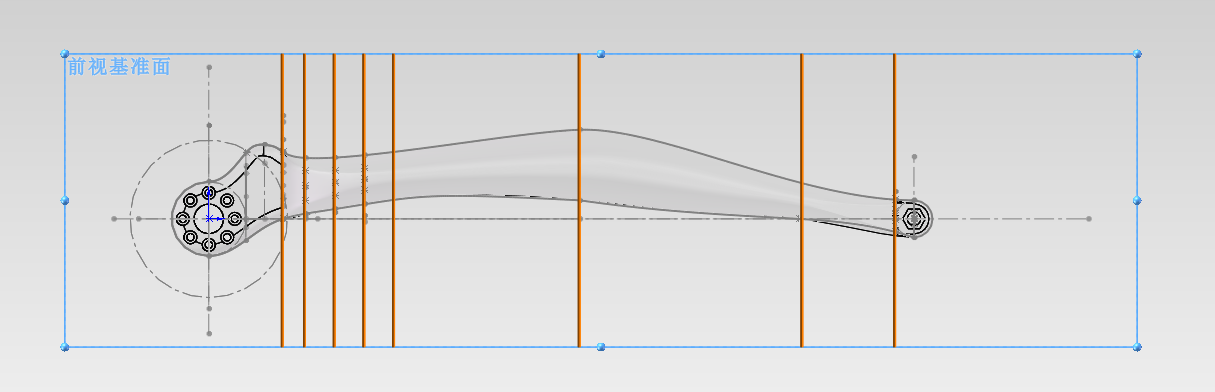
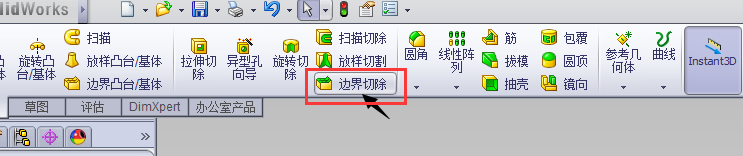
接下来,我们就来使用 边界切除 工具,将这个实体中间掏空:
然后在 方向1 里面,按照顺序添加已经绘制好的草图:
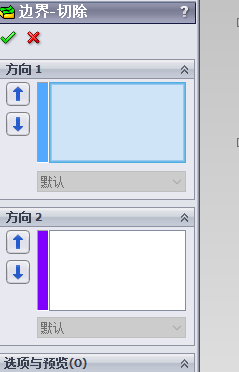
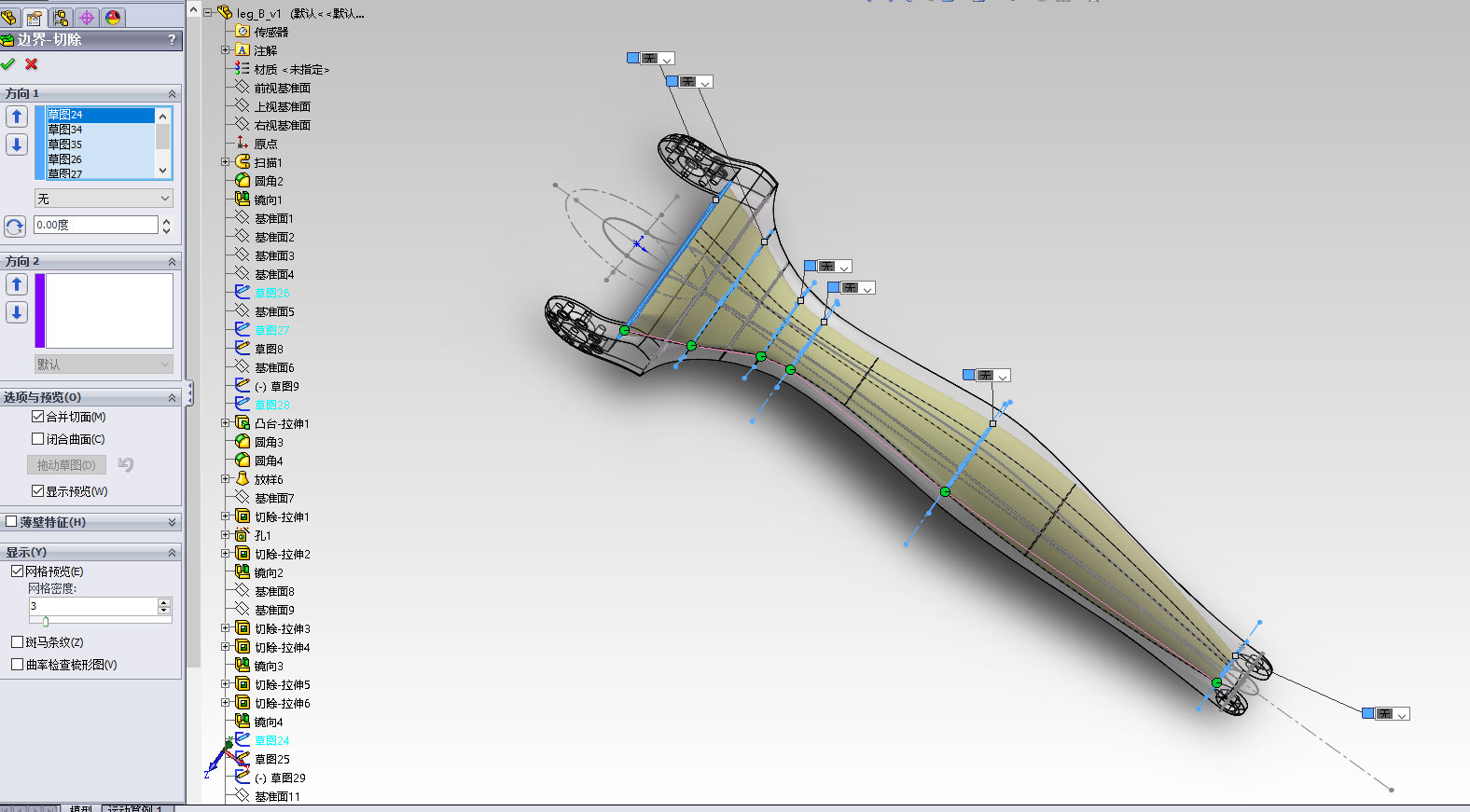
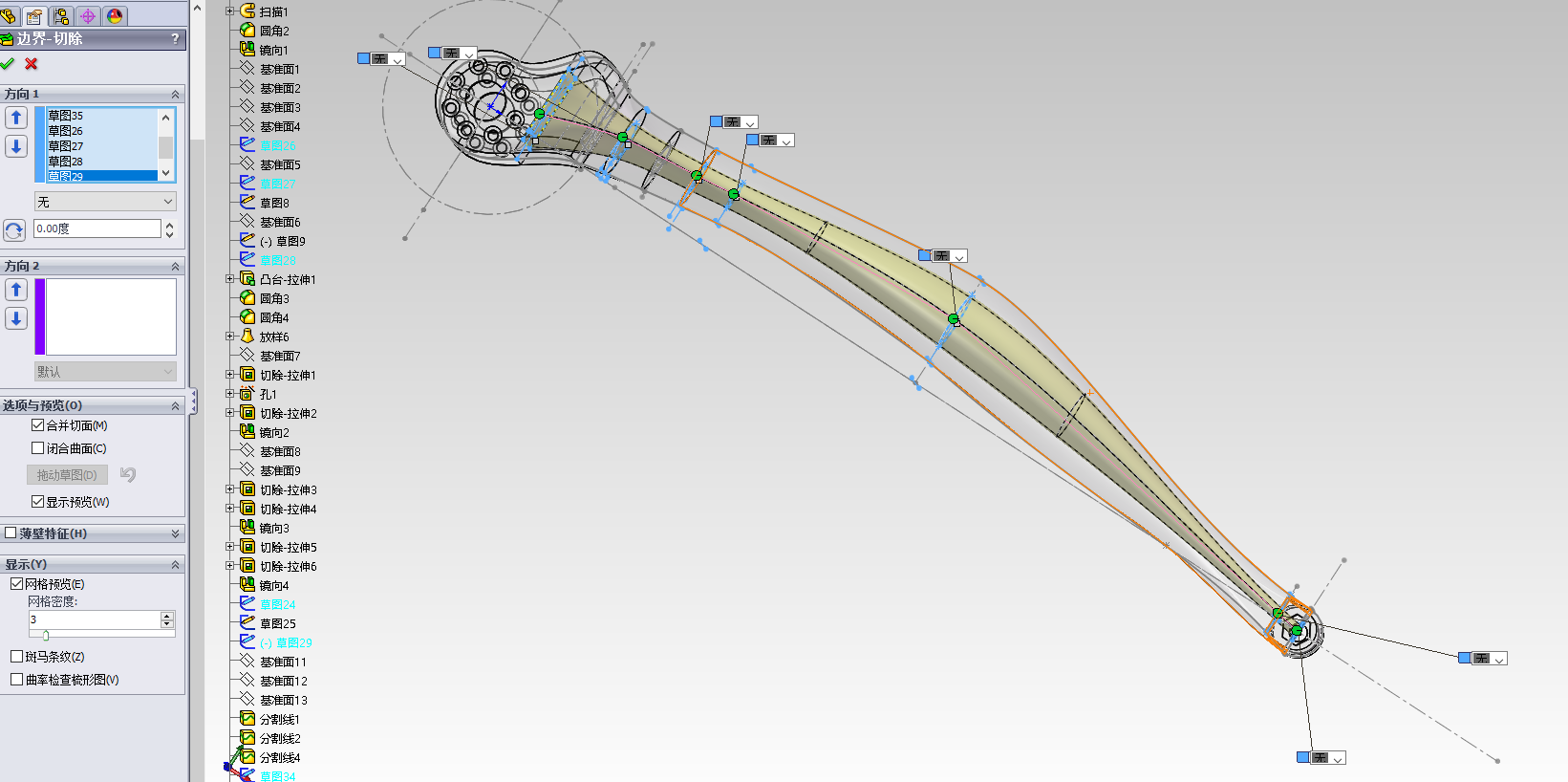
最后 确定 即可。
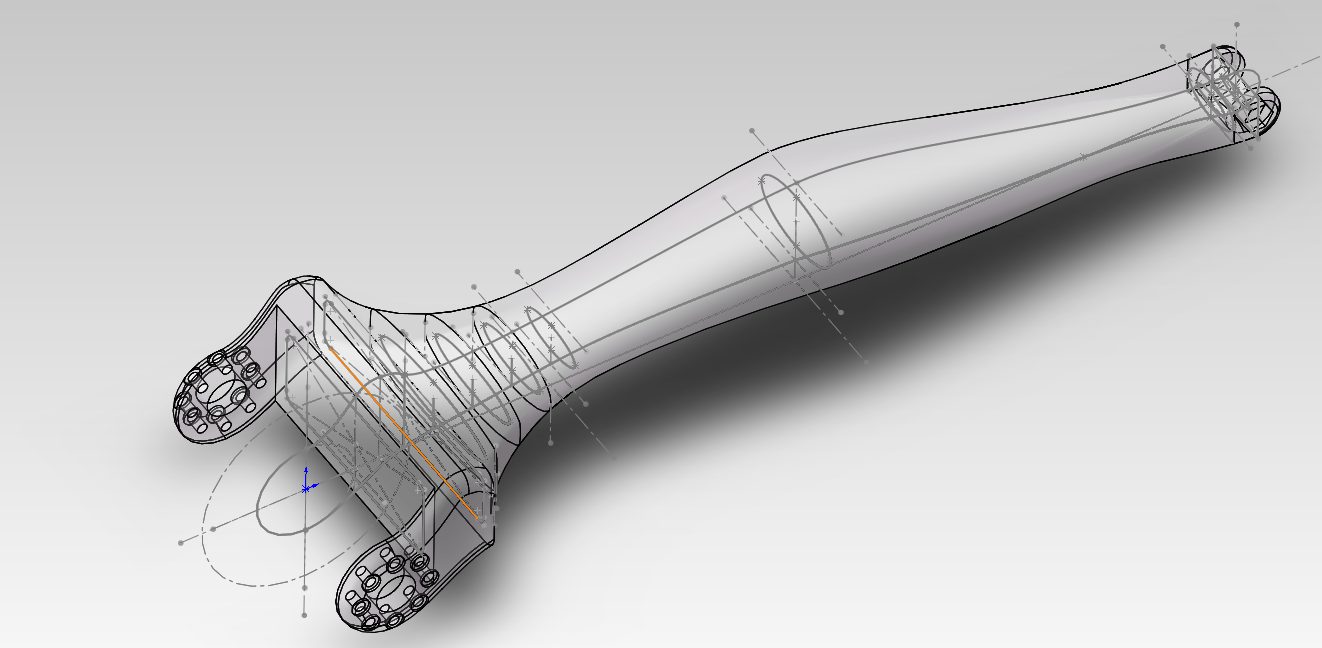
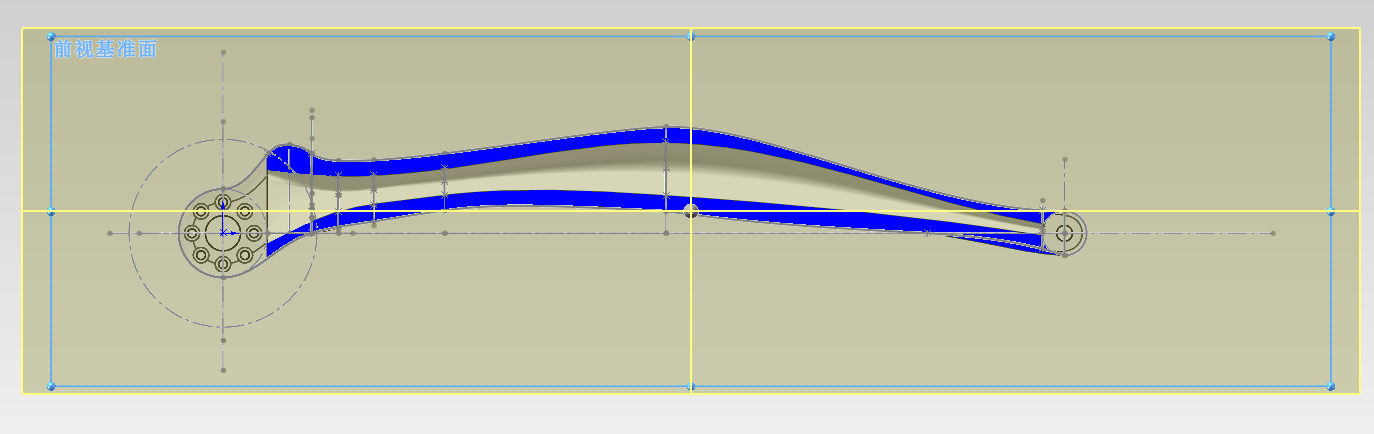
完成后,我们看看横切面图:
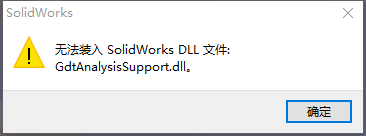
昨天做好的零件文件,今天睡醒了,再次打开, 就出现了这个问题:无法装入 SolidWorks.dll文件:GdtAnalysisSupport.dll
参考网站:http://jingyan.baidu.com/article/72ee561a530355e16138dfd4.html
参考
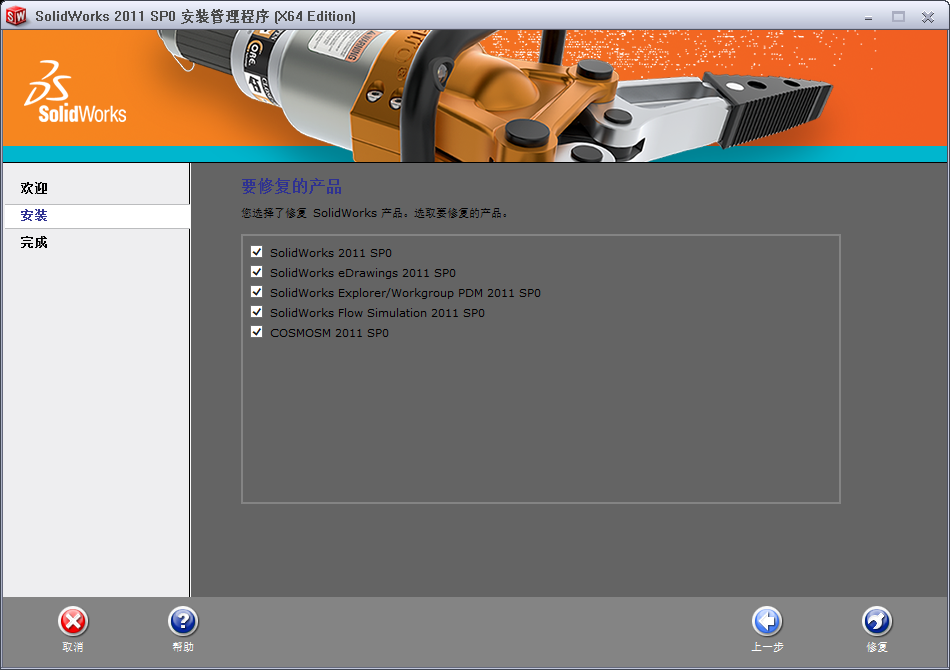
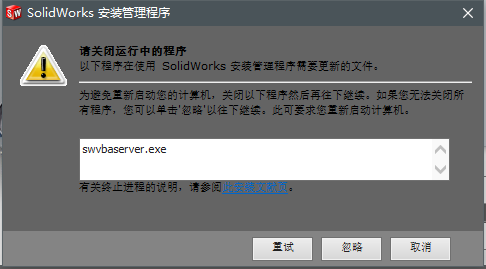
直接点击 忽略 :
等待大约5分钟:
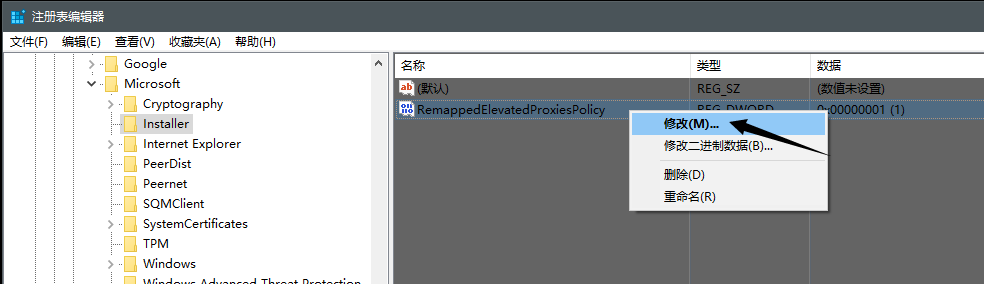

现在启动 SolidWorks 软件:
所以,你需要重新破解:
参考网站:
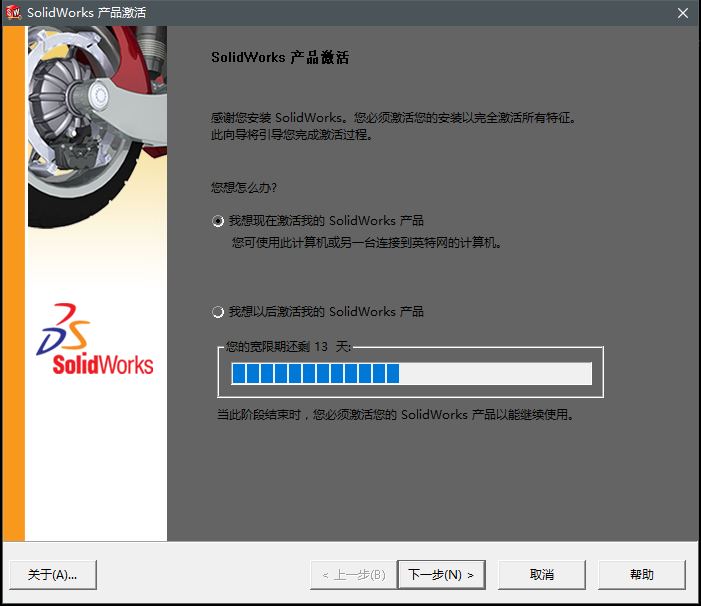
现在我们想点击 我想以后激活我的SolidWorks产品,来看看上面出现的问题是否解决了。
问题仍然存在:
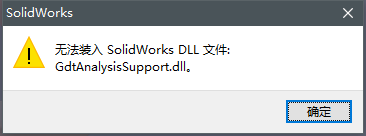
操了!
我知道怎么回事了。在注册表编辑器 里面添加Installer的路径错了。
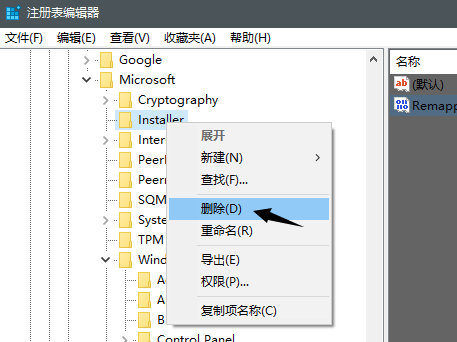
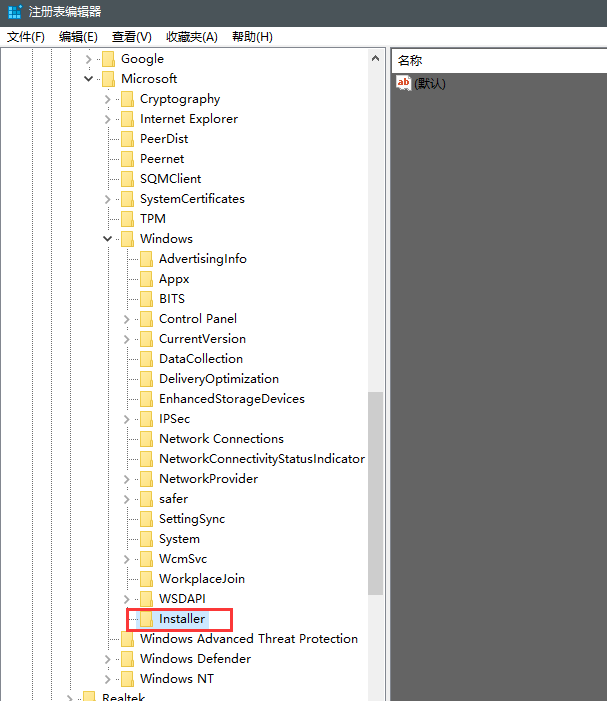
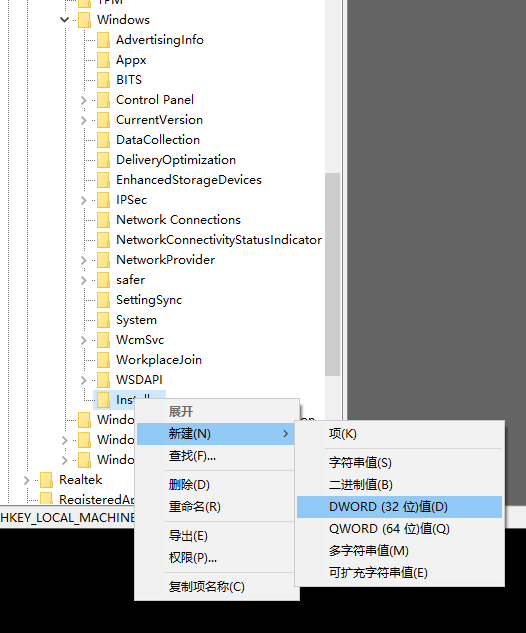
现在,GdtAnalysisSupport.dll文件的这个问题已经被解决了。现在SolidWorks软件是未被激活的状态,我们需要将其激活,激活的方法很简单,只需要到这个下载破解文件:

然后将这个下载后的压缩包解压,然后将里面的setup文件夹整个复制到你安装SolidWorks软件的路径下, 我当前安装的路径是:C:\Program Files\SolidWorks Corp\SolidWorks。这个路径里面原本就是有一个setup文件夹。我们在复制的时候,电脑会提示我们,我们直接选择替换即可。现在无需重启电脑,直接启动SolidWorks软件,现在软件就不会在提示你激活软件了。
现在,这个问题是不在出现了,但是,我之前做好的模型,还是有一部分步骤都失效了。这是怎么回事。
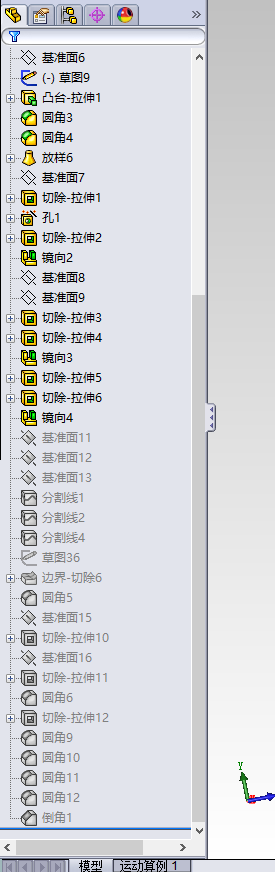
我现在没有办法了,现在的办法是:安装更新的SolidWorks 软件(2016)
请参考这篇笔记:Windows 10 安装 SolidWorks 2016 Sp5.0
2017-2-18 16:12:01
其实可以不用安装 SolidWorks 2016软件,我知道为什么打开的模型会是上面这个样子的了:
那些 “失效” 的步骤其实是 被 压缩 了。
解决办法就是:我们只需要将这些“失效”的步骤给 解除压缩即可。
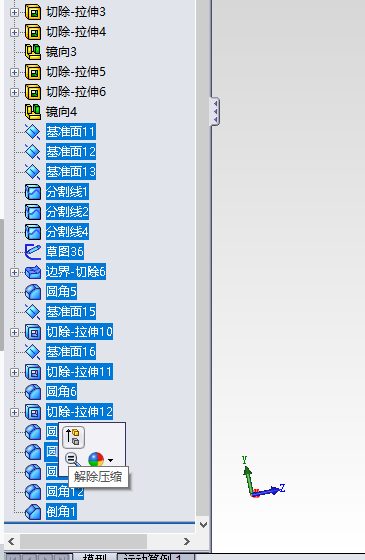
问题解决: