[TOC]
开发环境
Python第三方库:lxml、Twisted、pywin32、scrapy
Python 版本:python-3.5.0-amd64
PyCharm软件版本:pycharm-professional-2016.1.4
电脑系统:Windows 10 64位
如果你还没有搭建好开发环境,请到这篇博客 。
本篇博文的重点内容:
有一些数据,在源码上找不到的,这个时候需要使用 — 抓包。
Python调用MySQL数据库
本爬虫项目的目的是:某个关键字在淘宝上搜索到的所有商品,获取所有商品的: 商品名字、商品链接、商品价格、商品的评论。
开始实战
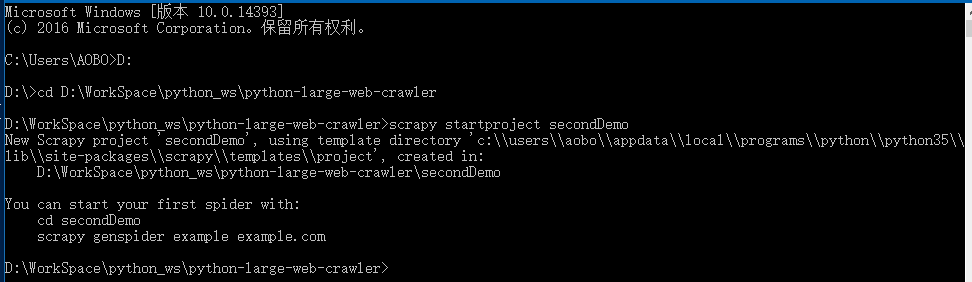
创建一个爬虫项目
1
scrapy startproject thirdDemo
设置防反爬机制(settings.py 文件)
请参考这篇博客:给 Scrapy 爬虫项目设置为防反爬 。
分析网站
1 . 分析网页界面:
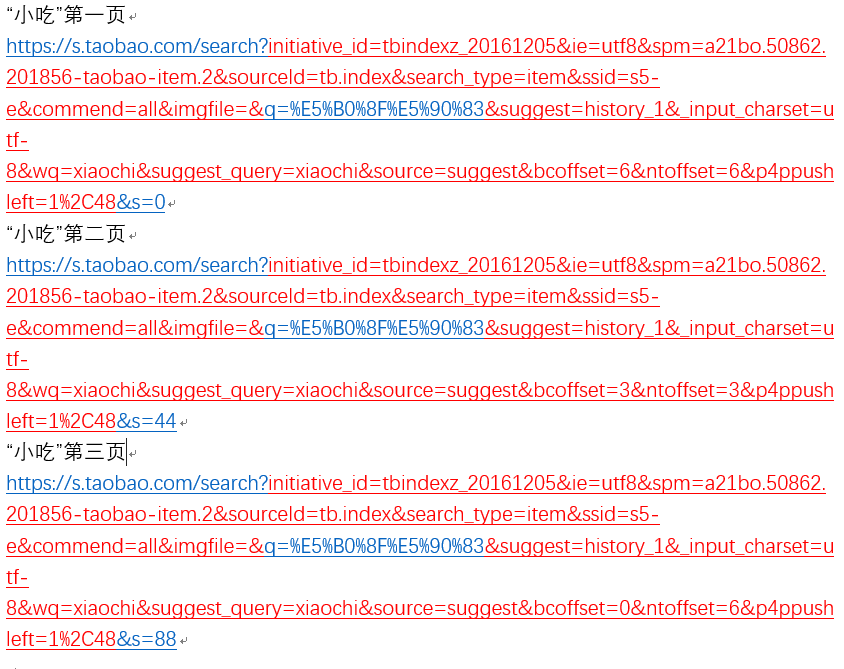
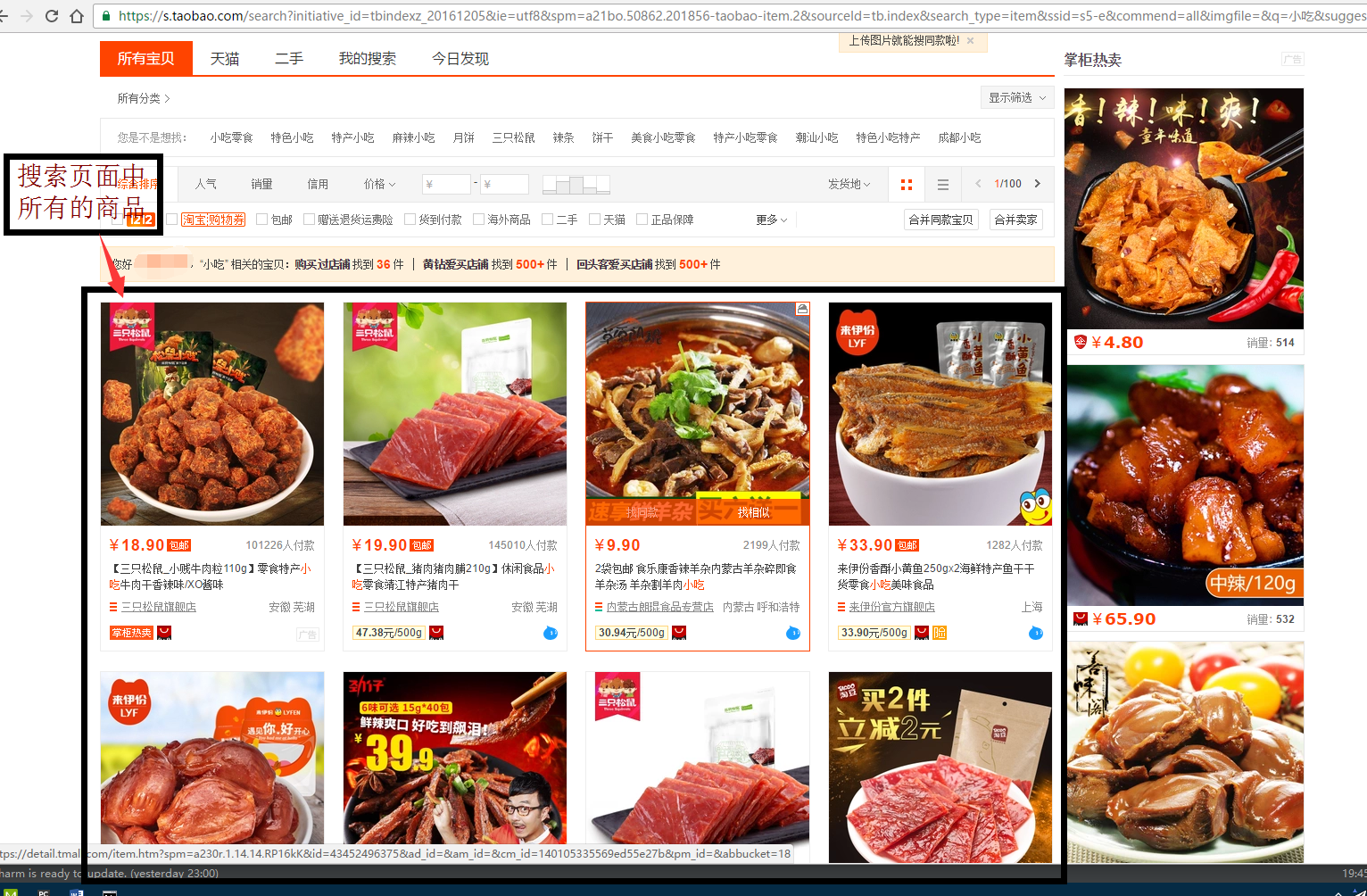
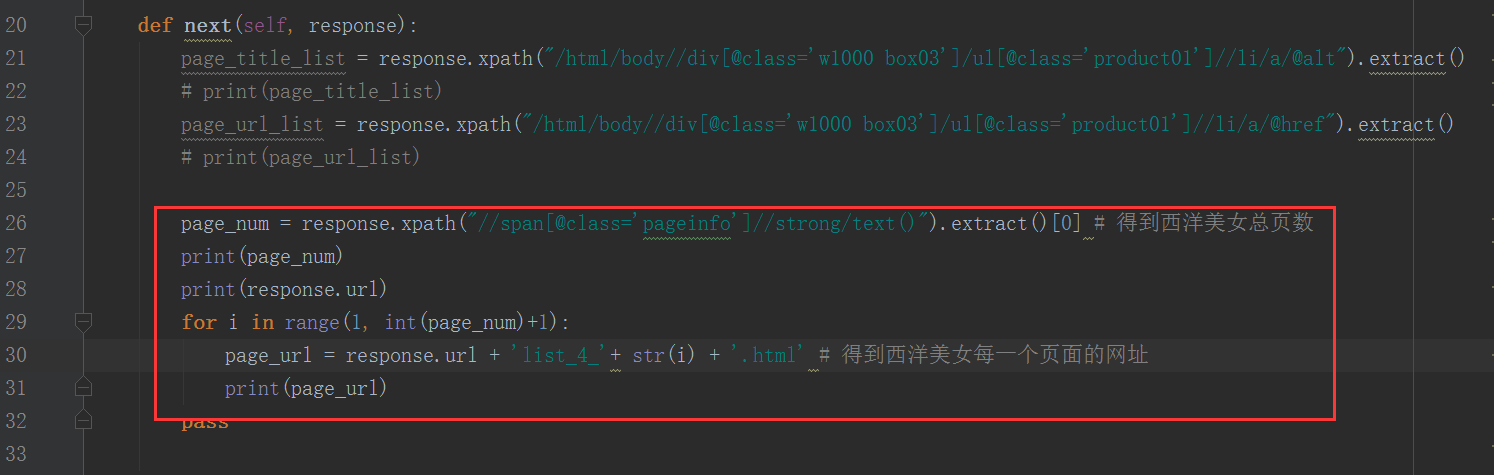
我们在淘宝网的搜索栏里面搜索关键字,比如“小吃”。它一共会输出100页。
可见:100页的搜索结果是淘宝的上限。(最多100页)
2 . 分析网址结构:
当我们点击页面进行浏览时,我们发现不同的页面的网址有规律,并且下面是我们找到的规律:
红色部分是一模一样的。
删除红色部分,将剩下的组成网址,一样可以正常的浏览原网页。
q= 后面是“小吃”的编码形式。s= 后面的数值等于 44*(当前页面-1)
开始写爬虫程序(taobao.py 文件)
创建一个爬虫文件(taobao.py 文件)
1
2
cd thirdDemo
scrapy genspider -t basic taobao taobao.com
使用PyCharm软件开发,使用PyCharm软件打开 thirdDemo 项目。
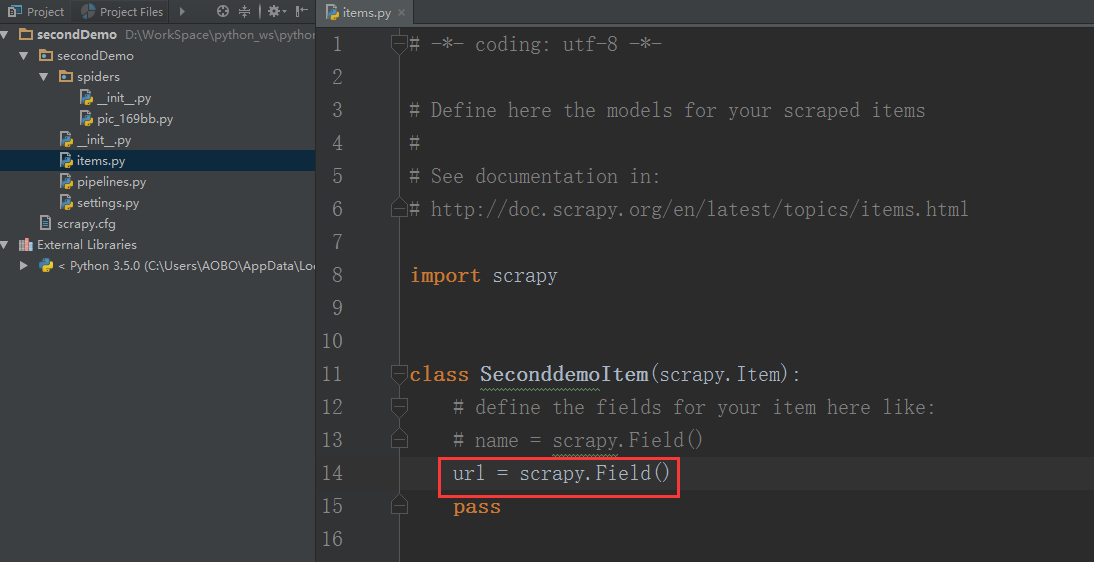
添加需要使用的存储容器对象(items.py文件)
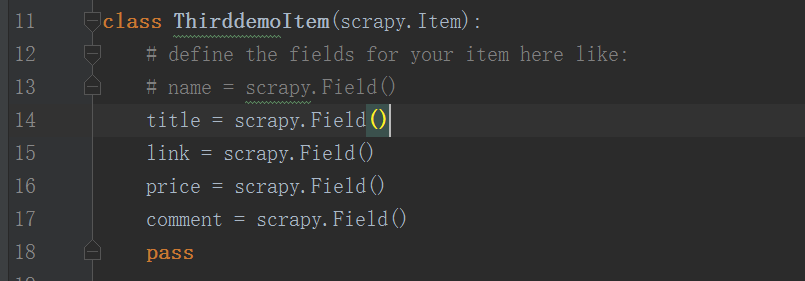
先到 items.py 文件里面的ThirddemoItem()函数里面创建存储用到容器(类的实例化对象)
1
2
3
4
5
6
7
8
class ThirddemoItem ( scrapy . Item ):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy . Field ()
link = scrapy . Field ()
price = scrapy . Field ()
comment = scrapy . Field ()
pass
得到搜索关键字对应的所有搜索页面(taobao.py文件)
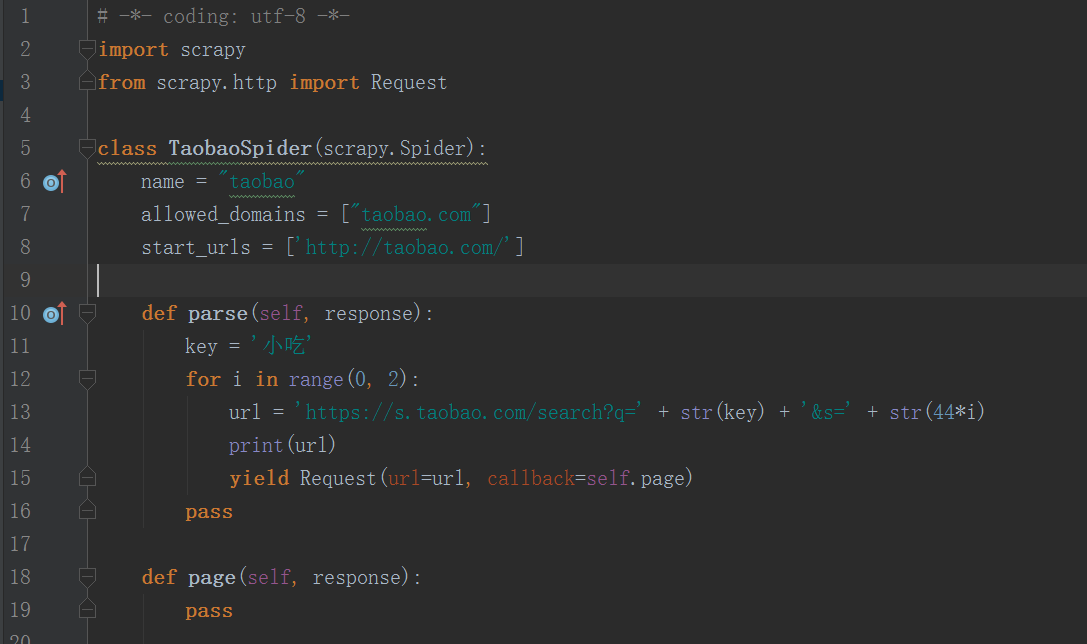
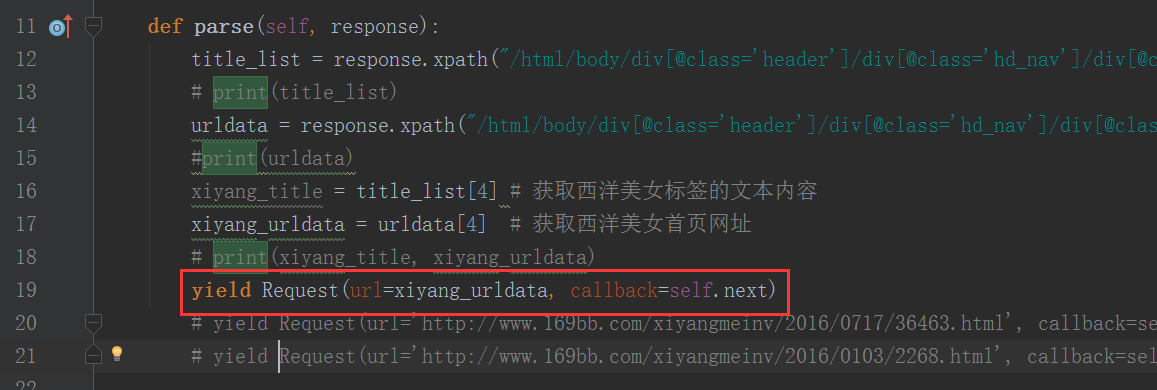
在回调函数parse()中,建立一个变量(key)来存储关键词(零食)。然后在使用一个for循环来爬取所有的网页。然后使用scrapy.http里面的Request 来在parse()函数返回(返回一个生成器(yield))一个网页源代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
class TaobaoSpider ( scrapy . Spider ):
name = "taobao"
allowed_domains = [ "taobao.com" ]
start_urls = [ 'http://taobao.com/' ]
def parse ( self , response ):
key = '小吃'
for i in range ( 0 , 2 ):
url = 'https://s.taobao.com/search?q=' + str ( key ) + '&s=' + str ( 44 * i )
print ( url )
yield Request ( url = url , callback = self . page )
pass
def page ( self , response ):
pass
(注意:我们上面通过观察网页已经知道了,搜索得到的页面有100页,但是我们现在是测试阶段,不爬这么多页,上面的代码我们只爬了2页)
运行一下:
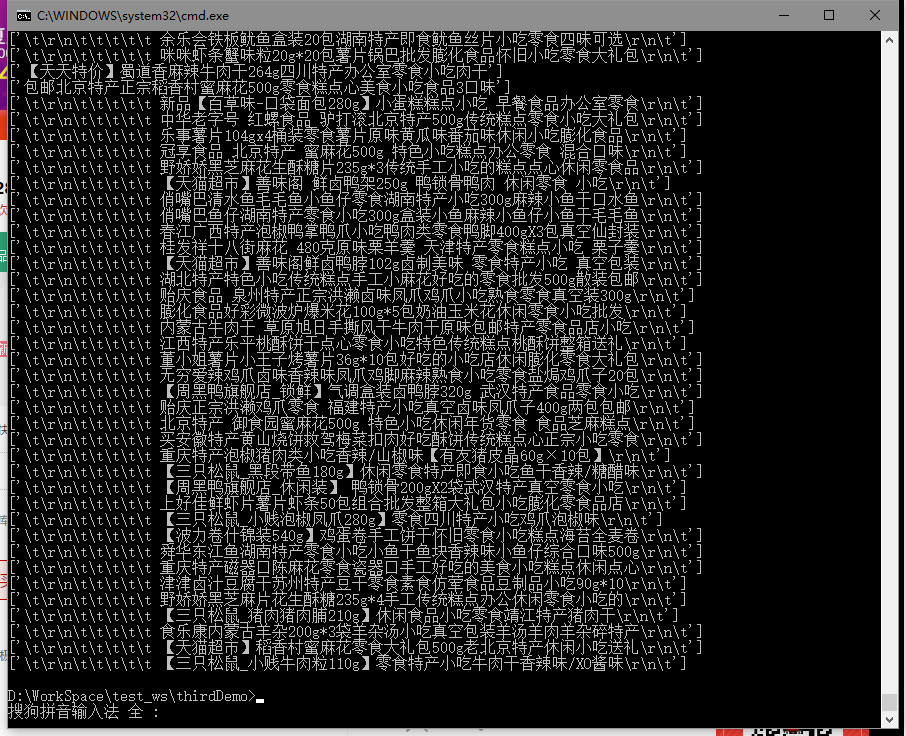
程序没有问题。
得到所有商品的id
我们现在的目标是得到搜索页面中所有商品的链接。
现在,我们观察搜索页面的源代码,我们找这些商品链接的规律,能否通过什么商品id之类的信息,然后通过商品id来构造出商品的链接网址。
幸运的是:确实可以这么做。
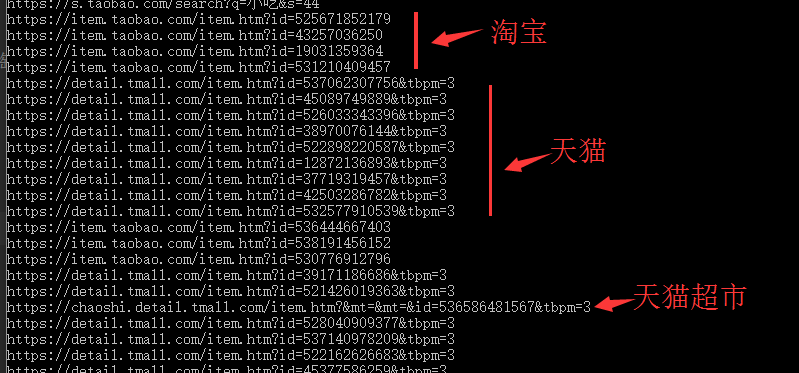
我发现,不管是搜索的商品,不管是在淘宝里、天猫里、天猫超市里,商品的链接网址都可以用下面的格式去构造:
1
https : // item . taobao . com / item . htm ? id = 商品的 id
所以,现在我们要做的是:先提取商品的id:(使用正则表达式)
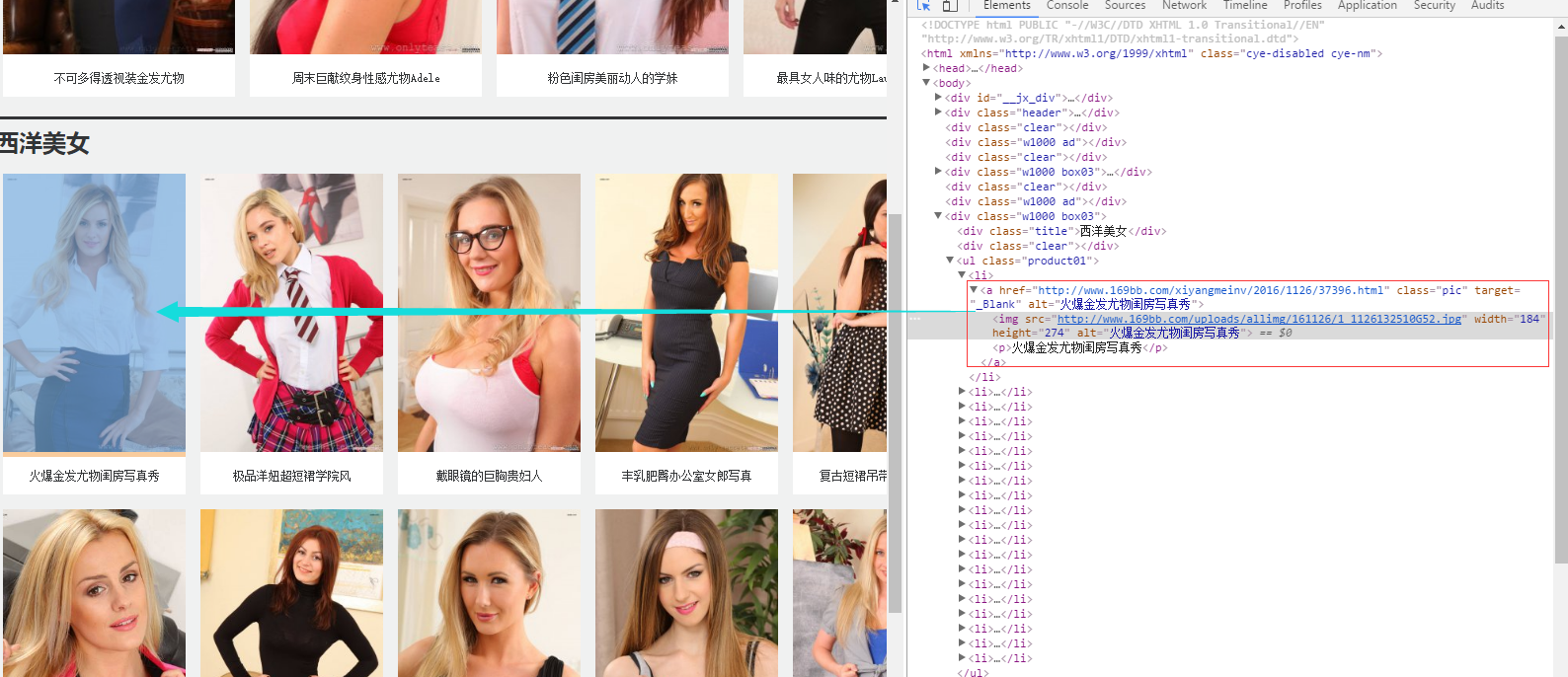
对搜索结果的网页随便一个地方右键:查看网页源代码(V) :
(我发现:通过在浏览器中按F12 和 右键来 查看网页源代码 这两种查看源代码得到的源代码不一样,后者得到的源代码和爬虫爬取的源代码一致,而前者和爬虫爬取的不一致。)
所有我们不能使用Xpath 表达式来用过标签获取商品id了。只能使用正则表达式 了。
我想可能的原因是:搜索页面可能是动态构造出来的,所以使用Xpath 表达式是不能对这种网址的源码进行提取信息的。(我瞎想的,不知道是否正确。不过事实其实是:使用Xpath 表达式是提取不了有效信息的。)
然后随便点击进入一个商品的链接网页,在这个网页的网址里面就可以找到这个商品的id:
然后在刚刚打开的源代码中,查找这个id:
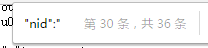
我们通过观察发现,使用"nid":"就可以找到这个搜索结果页面里面所有商品的id:
这个页面里面一共是36个商品,没错。
Q: 你可能发现了,这个搜索网页里面搜索到结果是48个商品,我们得到的是36个,是不是少了?
A: 没有少,这就是淘宝的营销策略。一个搜索页面一共有48个商品,但是其中有10多个商品是重复的!其中甚至有个商品在这个搜索页面中重复出现了三次,不信,你可以仔细的找找。
所以,商品的id可以使用下面的正则表达式 获取:
我们在page()方法中得到爬取到的网页源代码的 body 标签里面的所有信息:
先声明一点:
爬取到的网页源代码是:以网页源代码中指定的编码方式编码得到的bytes信息。
我们需要得到对应的解码信息:
参考网站:Python3 bytes.decode()方法
1
body = response . body . decode ( 'utf-8' )
response.body 它默认是二进制格式,所以我们在使用它之前要给它解码:decode('utf-8'),为了避免出错,我给它传第二个参数:ignore。
page()函数中的代码现在是下面这个样子的:
1
2
3
4
5
6
def page ( self , response ):
body = response . body . decode ( 'utf-8' , 'ignore' )
pattam_id = '"nid":"(.*?)"'
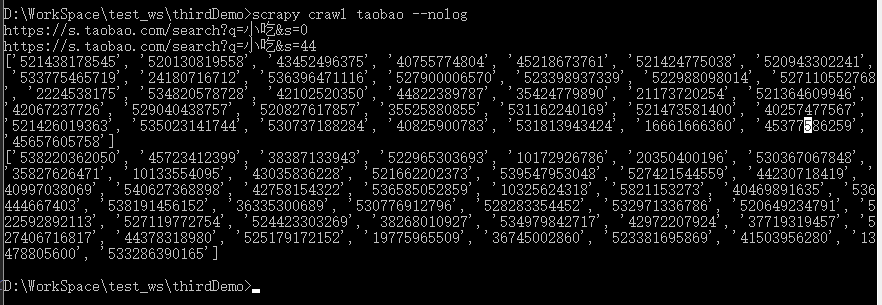
all_id = re . compile ( pattam_id ) . findall ( body )
print ( all_id )
pass
运行试试看:
得到所有商品的链接网址
现在得到了所有商品的ip,现在通过这些ip,构造出所有商品的网址。得到了链接后,就可以去爬这个网页的源代码了:(下面的代码中,在next()方法中将商品的网页网址打印了出来)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def page ( self , response ):
body = response . body . decode ( 'utf-8' , 'ignore' )
pattam_id = '"nid":"(.*?)"'
all_id = re . compile ( pattam_id ) . findall ( body )
# print(all_id)
for i in range ( 0 , len ( all_id )):
this_id = all_id [ i ]
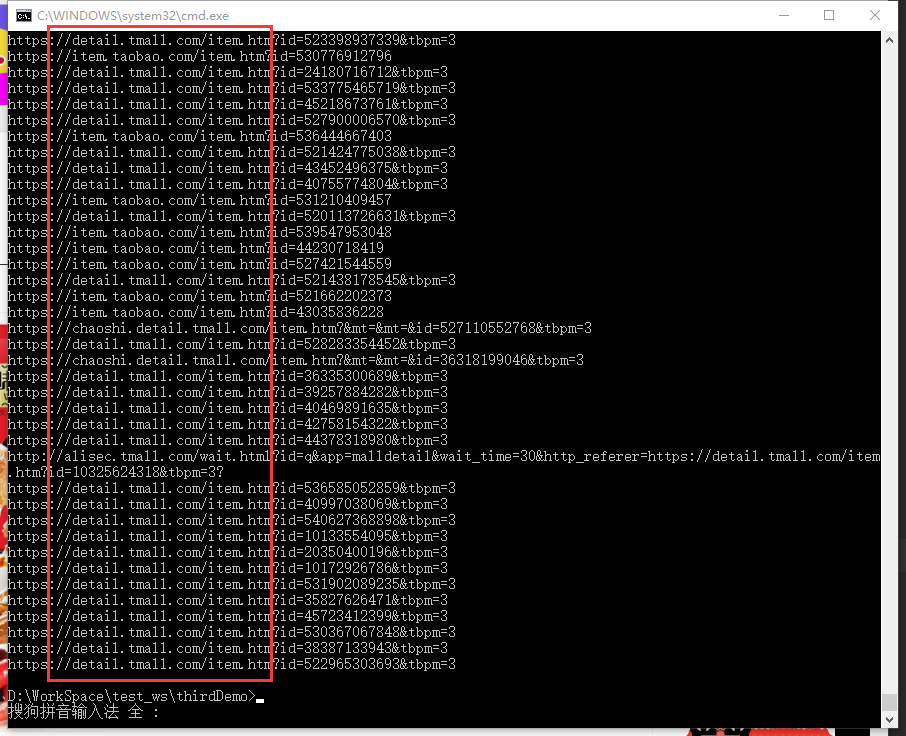
url = 'https://item.taobao.com/item.htm?id=' + str ( this_id )
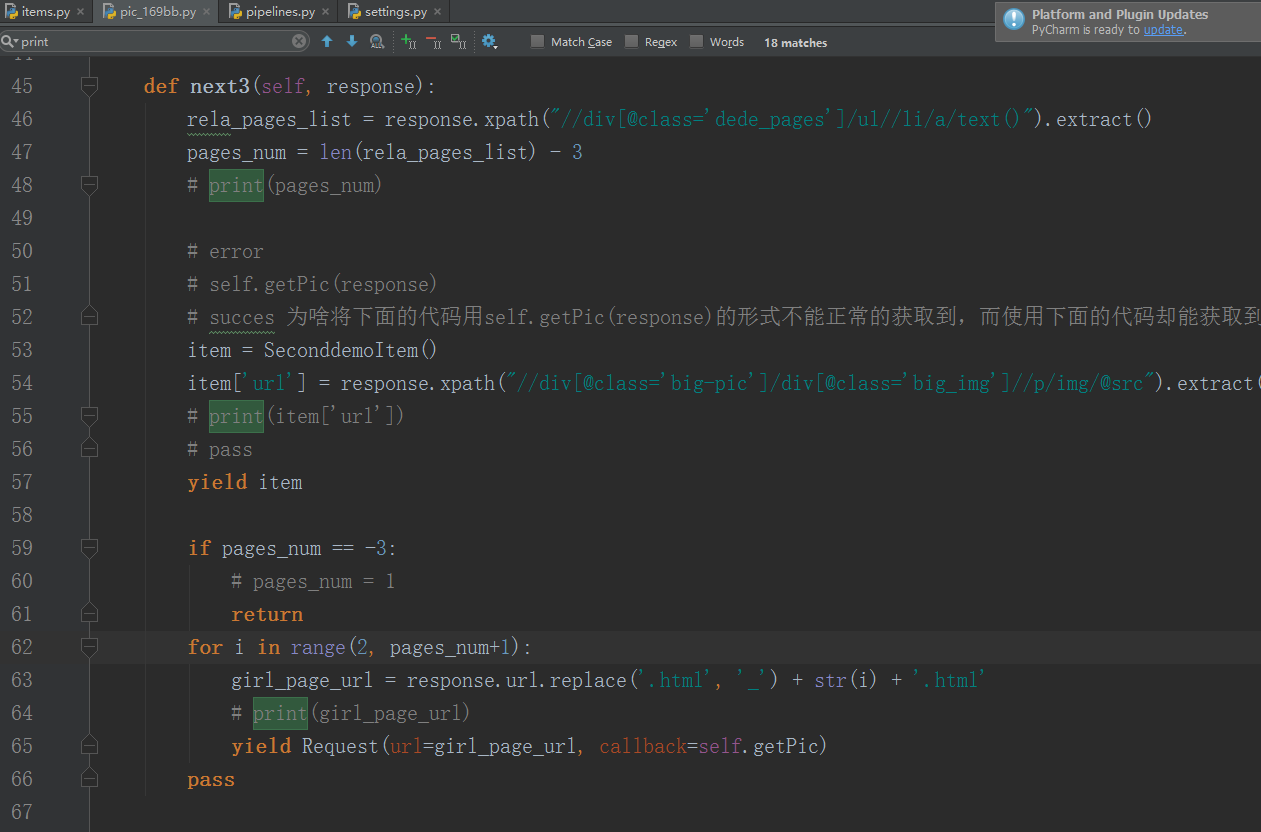
yield Request ( url = url , callback = self . next )
pass
pass
def next ( self , response ):
print ( response . url )
pass
运行试试看:(自动的将网址调整到正确的网址上。比如天猫 或者天猫超市 之类的子域名)
获取商品的具体信息(taobao.py 文件)
获取商品的名字
现在在next()回调函数中实例化一个开始时在items.py文件里面创建的项目的存储容器对象。然后,我们就可以直接使用它了。
所以现在在 taobao.py 文件的上面添加这个文件:
1
from thirdDemo.items import ThirddemoItem
现在我们要得到商品的标题。
我们尽量从源代码中的信息提取,如果源代码中没有的信息,我们在使用抓包的凡是提取。
标题是可以直接在源代码中提取的:(观察网页源代码,直接中Xpath表达式)
天猫或者天猫超市的商品的标题可以使用下面的Xpath 表达式提取:
1
title = response . xpath ( "//div[@class='tb-detail-hd']/h1/text()" ) . extract ()
淘宝的商品的标题可以使用下面的Xpath 表达式提取:
1
title = response . xpath ( "//h3[@class='tb-main-title']/@data-title" ) . extract ()
所以,这里提取标题,我们需要一个判断语句,判断这个商品的网址链接是天猫的还是淘宝的。
伪码如下:
1
2
3
4
if 不是淘宝的网址 :
title = response . xpath ( "//div[@class='tb-detail-hd']/h1/text()" ) . extract () # 天猫或者天猫超市
else :
title = response . xpath ( "//h3[@class='tb-main-title']/@data-title" ) . extract () # 淘宝
我们的判断标准就是商品网址的子域名。子域名大致一共有三种:detail.tmall(天猫)、chaoshi.detail.tmall(天猫超市)、item.taobao(淘宝)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def next ( self , response ):
# print(response.url)
url = response . url
pattam_url = 'https://(.*?).com'
subdomain = re . compile ( pattam_url ) . findall ( url )
# print(subdomain)
if subdomain [ 0 ] != 'item.taobao' :
title = response . xpath ( "//div[@class='tb-detail-hd']/h1/text()" ) . extract ()
pass
else :
title = response . xpath ( "//h3[@class='tb-main-title']/@data-title" ) . extract ()
pass
self . num = self . num + 1 ;
print ( title )
pass
运行试试看:
有的时候,偶尔会得到几个 [],这是因为,你爬的太快的,淘宝的服务器没有同意你爬取这个商品的网页。(所以提高防反爬机制,效果会好一些。)
获取商品的链接网址(taobao.py 文件)
(直接得到)
1
item [ 'link' ] = response . url
获取商品的价格信息(原价)(taobao.py 文件)
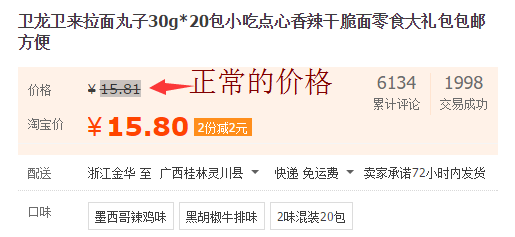
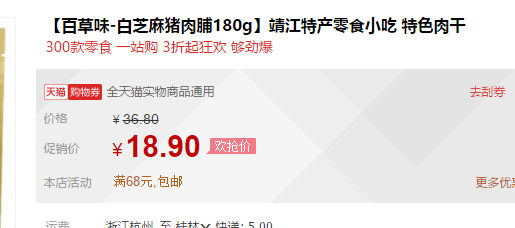
正常的价格可以在商品网页的源代码里面获取,但是淘宝价(促销价)在商品源代码里面没有,这时就需要通过抓包来获取。
淘宝:
天猫:
我们先获取正常的价格。这里也需要分淘宝和天猫,它们获取正常价格的Xpath 表达式或者正则表达式 不同。
注意:这里总结表达式,通过对商品页面右键 -> 查看网页源代码 的方式查看源代码。
1
2
3
4
5
6
7
8
if subdomain [ 0 ] != 'item.taobao' :
pattam_price = '"defaultItemPrice":"(.*?)"'
price = re . compile ( pattam_price ) . findall ( response . body . decode ( 'utf-8' , 'ignore' )) # 天猫
pass
else :
price = response . xpath ( "//em[@class = 'tb-rmb-num']/text()" ) . extract () # 淘宝
pass
print ( price )
提取商品的累计评论数量:(使用抓包的方式)(taobao.py 文件)
淘宝:
天猫:
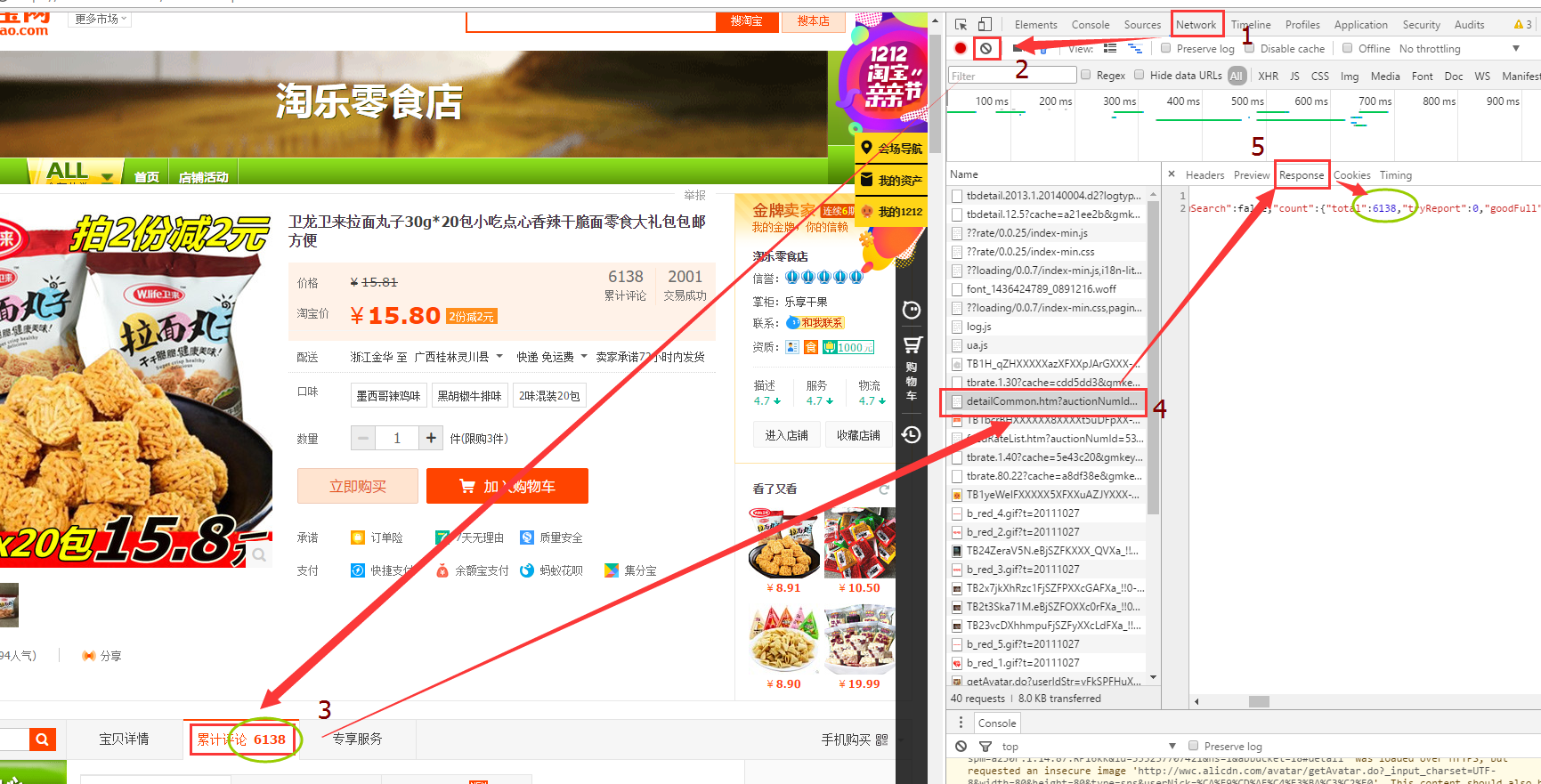
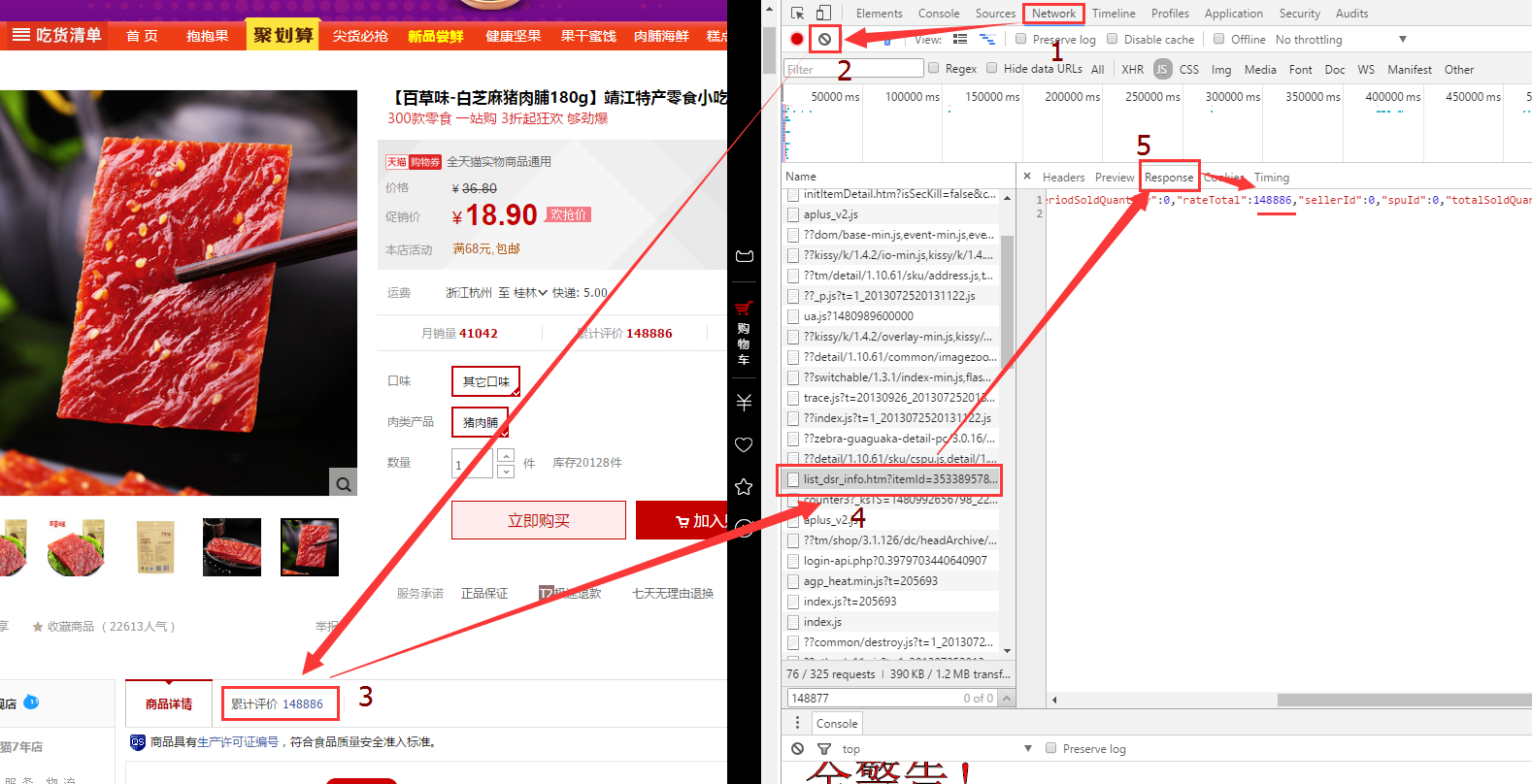
可以使用 : Fiddler4抓包软件 或者 浏览器按F12->Network->Name->Response 查看抓包信息
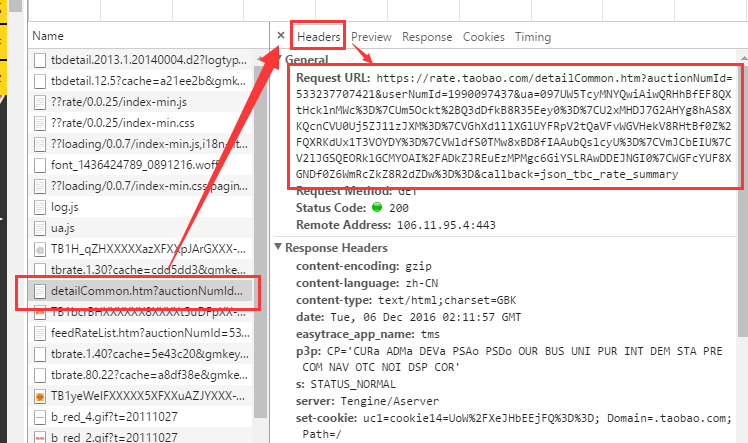
这里,我通过浏览器进行抓包,找到了评论数所在的包:(一个一个的找)
淘宝:
观察这个包的网址:
这个网址,我们可以在浏览器中复制,再访问以下:(是可以正常访问的)
https://rate.taobao.com/detailCommon.htm?auctionNumId=533237707421&userNumId=1990097437&ua=097UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5Ockt%2BQ3dDfkB8R35Eey0%3D%7CU2xMHDJ7G2AHYg8hAS8XKQcnCVU0Uj5ZJ11zJXM%3D%7CVGhXd1llXGlUYFRpV2tQaVFvWGVHekV8RHtBf0Z%2FQXRKdUx1T3VOYDY%3D%7CVWldfS0TMw8xBD8fIAAubQslcyU%3D%7CVmJCbEIU%7CV2lJGSQEORklGCMYOAI%2FADkZJREuEzMPMgc6GiYSLRAwDDEJNGI0%7CWGFcYUF8XGNDf0Z6WmRcZkZ8R2dZDw%3D%3D&callback=json_tbc_rate_summary
我发现上面的这个网址可以缩减为:
https://rate.taobao.com/detailCommon.htm?auctionNumId=533237707421
https://rate.taobao.com/detailCount.do?_ksTS=1480993623725_99&callback=jsonp100&itemId=533237707421
而这个533237707421就是商品的id。好了,找到这个网址的规律,现在可以> 手动构造这个评论数的网址了:
天猫:
https://dsr-rate.tmall.com/list_dsr_info.htm?itemId=35338957824&spuId=235704813&sellerId=628189716&_ksTS=1480992656788_203&callback=jsonp204
可以缩减为:
https://dsr-rate.tmall.com/list_dsr_info.htm?itemId=35338957824
最后,我们发现:不管是淘宝还是天猫,都可以使用下面这个构造方式来得到含有正确评论数量的网址:
1
https : // dsr - rate . tmall . com / list_dsr_info . htm ? itemId = 商品 id
注意:使用https://rate.taobao.com/detailCommon.htm?auctionNumId=商品id 这种网址也可以,但是在对天猫商品得到评价数量和网页里面显示的不同。所以我们不使用这个构造方法。
所以通过商品id就可以得到含有评论数量信息的包的网址。现在在next()方法中需要通过商品的URL获取商品的id。
我们从上面的图中看到:天猫和淘宝的网址不同,所以,从网址中获取商品id的正则表达式也就不同。下面的代码的功能就是从商品的url中提取商品id:
1
2
3
4
5
6
7
8
9
10
11
# 获取商品的id(用于构造商品评论数量的抓包网址)
if subdomain [ 0 ] != 'item.taobao' : # 如果不属于淘宝子域名,执行if语句里面的代码
pattam_id = 'id=(.*?)&'
this_id = re . compile ( pattam_id ) . findall ( url )[ 0 ]
pass
else :
# 这种情况是不能使用正则表达式的,正则表达式不能获取字符串最末端的字符串
pattam_id = 'id=(.*?)$'
this_id = re . compile ( pattam_id ) . findall ( url )[ 0 ]
pass
print ( this_id )
注意:$ : 在正则表达式 里面的作用是:匹配字符串末尾。
举例:当url = 'https://item.taobao.com/item.htm?id=535023141744' 时,这是一个淘宝网站里面的一个商品,现在我们想得到这个网址里面的商品id。
如果你把正则表达式写成这个样子:pattam_id = 'id=(.*?)',是匹配不到结果的(商品id)。
正则表达式是通过字符串上下文来匹配你需要的信息的,如果只有“上文”,没有“下文”时,对于使用正则表达式匹配字符串末端字符串,需要在正则表达式中使用$。
运行试试看,一切都在掌控之中。
构造具有评论数量信息的包的网址,并获取商品的评论数量
得到目标抓包网址,获取它的源代码,然后提取评论数量:
1
2
3
4
5
6
7
8
9
10
# 构造具有评论数量信息的包的网址
comment_url = 'https://dsr-rate.tmall.com/list_dsr_info.htm?itemId=' + str ( this_id )
# 这个获取网址源代码的代码永远也不会出现错误,因为这个URL的问题,就算URL是错误的,也可以获取到对应错误网址的源代码。
# 所以不需要使用 try 和 except urllib.URLError as e 来包装。
comment_data = urllib . request . urlopen ( comment_url ) . read () . decode ( 'utf-8' , 'ignore' )
pattam_comment = '"rateTotal":(.*?),"'
comment = re . compile ( pattam_comment ) . findall ( comment_data )
# print(comment)
item [ 'comment' ] = comment
现在返回item对象:
现在,我们就可以在pipline.py文件里面来对我们得到的这些商品数据进行一些操作了,比如打印到终端或者保存到数据库中。
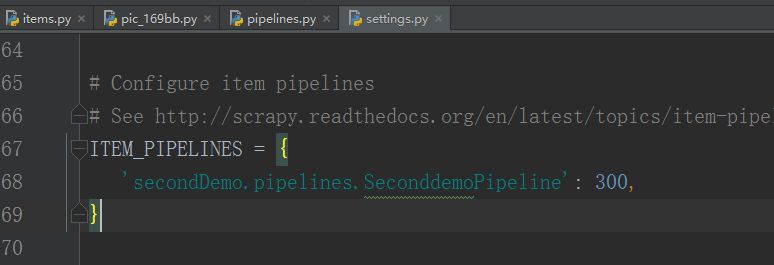
但在这之前,我们需要设置一下settings.py文件,将下面的代码的注释去掉:
在pipline.py文件中对taobao.py爬虫文件返回的item对象进行处理(比如打印到终端,或者保存到数据库中)
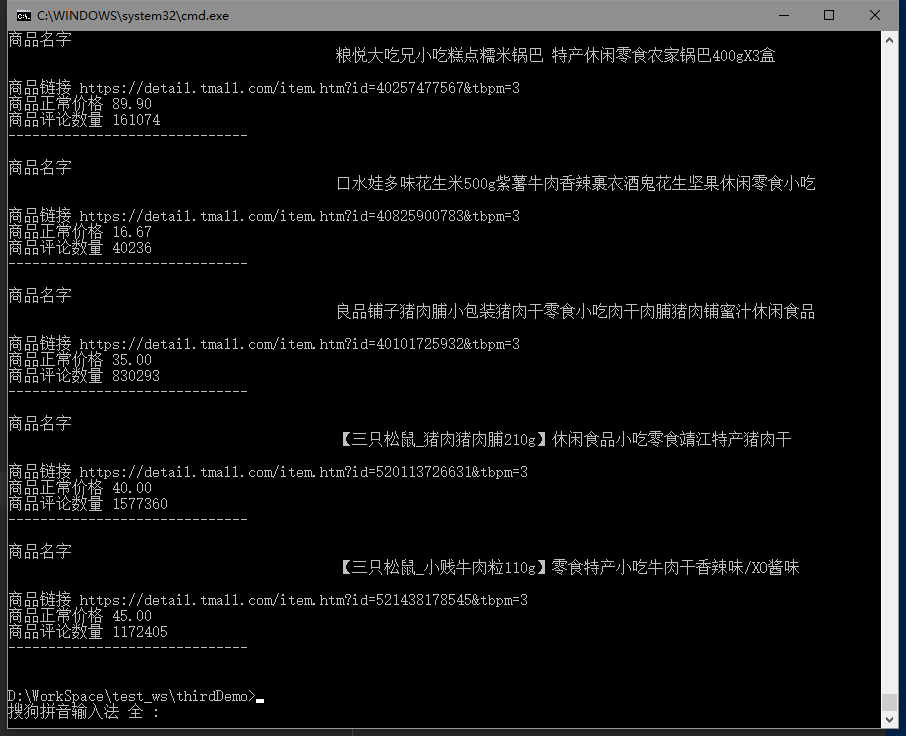
将得到的信息打印到终端中:
1
2
3
4
5
6
7
8
9
10
11
12
class ThirddemoPipeline ( object ):
def process_item ( self , item , spider ):
title = item [ 'title' ][ 0 ]
link = item [ 'link' ]
price = item [ 'price' ][ 0 ]
comment = item [ 'comment' ][ 0 ]
print ( '商品名字' , title )
print ( '商品链接' , link )
print ( '商品正常价格' , price )
print ( '商品评论数量' , comment )
print ( '------------------------------ \n ' )
return item
运行试试看:
下面是将得到的信息保存到数据库中的操作:
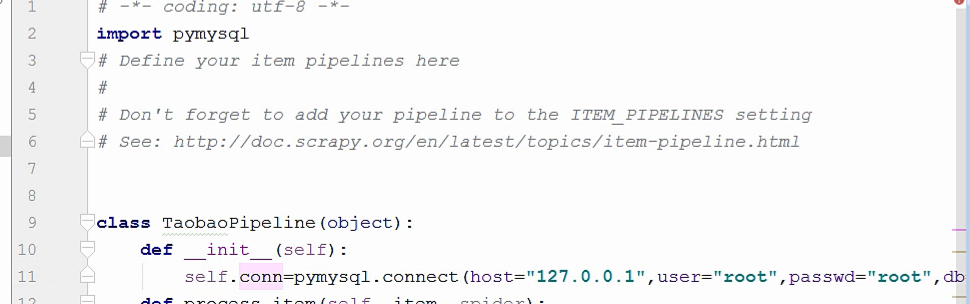
第一件事情就是 启动数据库,启动数据库的代码一般我们是将它写到默认的__init__(self)函数中,这个方法就是最开始做的事情。
要想连接到数据库,首先要有数据库:使用MySQL数据库
在python上要想使用MySqL数据库,需要先安装pymysql库这个模块。
有打开数据库的函数,就要有关闭数据库的方法。
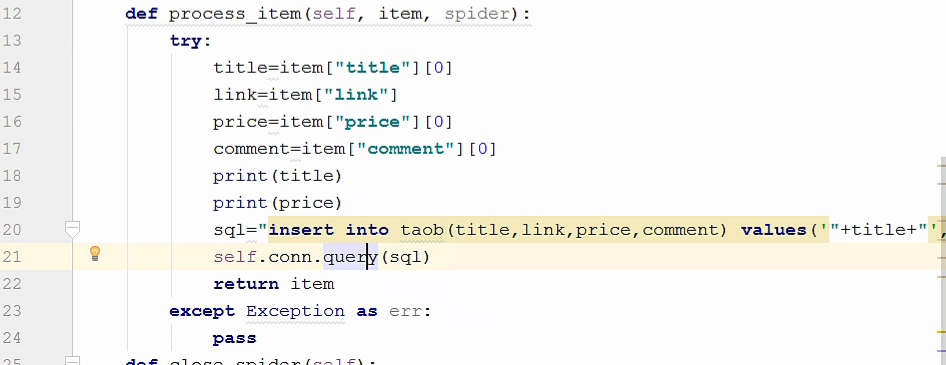
现在,我们在process()函数中处理数据,将数据插入到数据库里面。并且加一个异常处理,因为我不希望程序运行的时候会出现错误而终止,并且我也不想