1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
| D:\WorkSpace\python_ws\python-large-web-crawler\firstdemo>scrapy crawl csdn
2016-11-26 00:37:58 [scrapy] INFO: Scrapy 1.2.1 started (bot: firstdemo)
2016-11-26 00:37:58 [scrapy] INFO: Overridden settings: {'SPIDER_MODULES': ['firstdemo.spiders'], 'BOT_NAME': 'firstdemo', 'NEWSPIDER_MODULE': 'firstdemo.spiders'}
2016-11-26 00:37:58 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.logstats.LogStats',
'scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2016-11-26 00:37:59 [scrapy] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2016-11-26 00:37:59 [scrapy] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2016-11-26 00:37:59 [scrapy] INFO: Enabled item pipelines:
['firstdemo.pipelines.FirstdemoPipeline']
2016-11-26 00:37:59 [scrapy] INFO: Spider opened
2016-11-26 00:37:59 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2016-11-26 00:37:59 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2016-11-26 00:37:59 [scrapy] DEBUG: Crawled (200) <GET http://blog.csdn.net/> (referer: None)
第1篇文章:
JSTL 标签大全详解
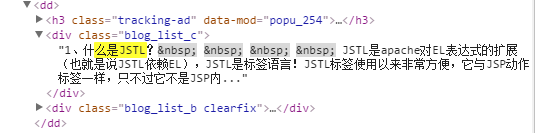
2016-11-26 00:37:59 [scrapy] ERROR: Error processing {'detail': ['1、什么是JSTL?\xa0 \xa0 \xa0 \xa0 '
'JSTL是apache对EL表达式的扩展(也就是说JSTL依赖EL),JSTL是标签语言!JSTL标签使用以来非常方便,它与JSP动作标签一样,只不过它不是JSP内...',
'你是否为调试第三方SDK时debug签名和release签名发生冲突而烦恼?你是否在debug时第三方功能测试通过,而release时无法使用?你是否在为对接微信、支付宝、地图因签名导致的问题而烦恼?...',
'Android图表库MPAndroidChart(十二)——来点不一样的,正负堆叠条形图\n'
' 接上篇,今天要说的,和上篇的类似,只是方向是有相反的两面,我们先看下效果 实际上这样就导致了我们的代码是...',
'一个类在被加载到内存之前要经过加载、验证、准备等过程。经过这些过程之后,虚拟机才会从方法区将代表类的运行时数据结构转换为内存中的Class。\n'
'\n'
'我们这节内容的重点在于一个类是如何被加载的,所以我们从类...',
'今天遇到一个问题是关于仿射变换的,但是由于没有将仿射变换的具体原理型明白,看别人的代码看的很费解,最后终于在师兄的帮助下将原理弄明白了,我觉得最重要的是理解 仿射变换可以看成是几种简单变换的复合实现,\n'
'...',
'开发环境准备首先你要搭建好React Native for Android开发环境, 没有搭建好的可以参考:React '
'Native for Android Windows环境搭建 用Android...',
'TCP三次握手四次挥手详解',
'秋招收官最后一战。\n'
'腾讯一面(电话):\n'
'自我介绍\n'
'项目,平时怎么学习?\n'
'设计模式 \n'
'(1)知道哪些设计模式?设计模式在Android、Java中是怎么应用的,每个都说一下? \n'
'(2)InputStre...',
'实现一个简单的呈现/解散动画效果,当呈现时,呈现的主要内容和背景要明显区分,背景呈现一个半透明遮罩效果,透过背景可以看到下层 '
'View Controller 的内容',
'概述前面的3篇博文分别对lazyAndroid的框架简介、元素抓取和核心API进行了说明,本文将基于框架给出的测试模板工程,详细阐述下使用该框架进行安卓UI自动化测试的步骤。',
'有时候我们想动态的根据一个资源名获得到对应的资源id,就可以使用getResources().getIdentifier()方法来获取该id。然后再使用该id进行相关的操作。\n'
'1、Demo示例\n'
' 下...',
'这篇应该是RecycleView的第四篇了,RecycleView真是新生代的宠儿能做这么多的事情。转载请注明作者AndroidMsky及原文链接 \n'
'http://blog.csdn.net/and...',
'提供:ZStack云计算 '
'前言版本控制,这是现代软件开发的核心需求之一。有了它,软件项目可以安全的跟踪代码变更并执行回溯、完整性检查、协同开发等多种操作。在各种版本控制软件中,git是近年来最流行的软...',
'相信有部分同学已经有耳闻了,前几天炒的很火一个消息,就是 Google 要推出一种全新的操作系统,取名 '
'Andromeda,这款新型的操作系统融合了 Android 和 Chrome OS,据称已经有...',
'Android7.0 Vold 进程工作机制分析之整体流程\n'
'\n'
'\n'
'\n'
'一、Vold简介\n'
'\n'
'Vold是Volume Daemon的缩写,负责管理和控制Android平台外部存储设备,包括SD插拨、挂载、卸载...',
'尊重原创,转载请标明出处\xa0\xa0\xa0\xa0http://blog.csdn.net/abcdef314159\n'
'Matrix是一个3*3的矩阵,通过矩阵执行对图像的平移,旋转,缩放,斜切等操作。先看一段代码 ...',
'Service后台服务、前台服务、IntentService、跨进程服务、无障碍服务、系统服务\n'
' 本篇文章包括以下内容:\n'
' \n'
' \n'
' 前言\n'
' Service的简介\n'
' 后台服务 \n'
' 不可交互...',
'借着今天“感恩节”,CSDN在此感谢每一位无私分享的博客作者。 \n'
' 他们笔耕不辍,在这里分享技术经验、自己走过的坑…… \n'
' 社区习惯了他们的存在,首页也需要他们的分享,他们无形中帮助了许多的开发...',
'Android图表库MPAndroidChart(十一)——多层级的堆叠条形图\n'
' 事实上这个也是条形图的一种扩展,我们看下效果就知道了 是吧,他一般满足的需求就是同类数据比较了,不过目前我还真没看...',
'相信大家应该都在使用 Android Studio 来开发 Android 了,如果你还没有的话,那么建议尽快迁移到 '
'Android Studio 上来,而且 Google 前段时间刚刚宣布,已经彻底...'],
'link': ['http://blog.csdn.net/qq_25827845/article/details/53311722',
'http://blog.csdn.net/yanzhenjie1003/article/details/53334071',
'http://blog.csdn.net/qq_26787115/article/details/53333270',
'http://blog.csdn.net/sahadev_/article/details/53334911',
'http://blog.csdn.net/q123456789098/article/details/53330484',
'http://blog.csdn.net/u011965040/article/details/53331859',
'http://blog.csdn.net/u010913001/article/details/53331863',
'http://blog.csdn.net/kesarchen/article/details/53332157',
'http://blog.csdn.net/kmyhy/article/details/53322669',
'http://blog.csdn.net/kaka1121/article/details/53325265',
'http://blog.csdn.net/ouyang_peng/article/details/53328000',
'http://blog.csdn.net/androidmsky/article/details/53306657',
'http://blog.csdn.net/zstack_org/article/details/53331077',
'http://blog.csdn.net/googdev/article/details/53331364',
'http://blog.csdn.net/qq_31530015/article/details/53324819',
'http://blog.csdn.net/abcdef314159/article/details/52813313',
'http://blog.csdn.net/qq_30379689/article/details/53318861',
'http://blog.csdn.net/blogdevteam/article/details/53322501',
'http://blog.csdn.net/qq_26787115/article/details/53323046',
'http://blog.csdn.net/googdev/article/details/53288564'],
'title': ['JSTL 标签大全详解',
'Android调试大法 自定义IDE默认签名文件',
'Android图表库MPAndroidChart(十二)——来点不一样的,正负堆叠条形图',
'一步步手动实现热修复(二)-类的加载机制简要介绍',
'仿射变换详解 warpAffine',
'React Native嵌入Android原生应用中',
'TCP三次握手四次挥手详解',
'腾讯Android面经',
'轻松实现部分背景半透明的呈现效果',
'APP自动化框架LazyAndroid使用手册(4)--测试模板工程详解',
'Android使用getIdentifier()方法根据资源名来获取资源id',
'Android基于RecyclerView实现高亮搜索列表',
'使用Git Hooks实现开发部署任务自动化',
'Andromeda OS 来了,Android 再见?',
'Android7.0 Vold 进程工作机制分析之整体流程',
'Android Matrix源码详解',
'Android四大组件——Service后台服务、前台服务、IntentService、跨进程服务、无障碍服务、系统服务',
'聚焦CSDN 2016博客之星,年终盛典!',
'Android图表库MPAndroidChart(十一)——多层级的堆叠条形图',
'Android 高效调试神器 JRebel']}
Traceback (most recent call last):
File "c:\users\aobo\appdata\local\programs\python\python35\lib\site-packages\twisted\internet\defer.py", line 649, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "D:\WorkSpace\python_ws\python-large-web-crawler\firstdemo\firstdemo\pipelines.py", line 15, in process_item
print(item['detail'][i])
UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 10: illegal multibyte sequence
2016-11-26 00:38:00 [scrapy] INFO: Closing spider (finished)
2016-11-26 00:38:00 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 211,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 13294,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2016, 11, 25, 16, 38, 0, 268302),
'log_count/DEBUG': 2,
'log_count/ERROR': 1,
'log_count/INFO': 7,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2016, 11, 25, 16, 37, 59, 190533)}
2016-11-26 00:38:00 [scrapy] INFO: Spider closed (finished)
D:\WorkSpace\python_ws\python-large-web-crawler\firstdemo>
|