参考网站:
要想给代码库贴标签,Github For Windows 软件上没没有这个按钮。你需要在Github For Windows 软件上打开 Git 命令行窗口,还是要使用命令行工具来完成这个工作。
1 2 | |
当你执行完git tag -a v1.0 -m "description information",想要查看一下,你可以执行:
1
| |
如果你执行完git tag -a v1.0 -m "description information",想要删除这个标签,可以执行:
1
| |
参考网站:
要想给代码库贴标签,Github For Windows 软件上没没有这个按钮。你需要在Github For Windows 软件上打开 Git 命令行窗口,还是要使用命令行工具来完成这个工作。
1 2 | |
当你执行完git tag -a v1.0 -m "description information",想要查看一下,你可以执行:
1
| |
如果你执行完git tag -a v1.0 -m "description information",想要删除这个标签,可以执行:
1
| |
随便编写一个Python类,类里面至少有下面三个函数:
1 2 3 4 5 6 7 8 9 10 | |
__init__() 函数就是类的构造函数。__repr__() 和 __str__() 函数 都是用来输出字符串用的。1 2 3 4 5 6 | |
本篇博客对 Python2 和 Python3 都适用。
copy命令比如现在,我想把这个路径F:\原文件夹里面的所有文件复制到这个路径F:\目标文件夹里面。可以在DOS命令行窗口里面执行:
1
| |
所以,我们要使用Python调用DOS命令行工具的步骤就两步:
os.system()函数执行命令字符串。我们使用python调用Windows系统DOS命令行里面的copy工具来进行文件的复制。代码如下:
适合在Python3中执行的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
上面的代码如果在python2中执行,不将第10行的注释去掉的话,会因为字符串编码和解码的不正确问题,导致系统找不到指定的路径。:
1 2 | |
第一件事 . 在DOS 里面,执行下面的命令,有的是对的,有的是错的:
1 2 3 4 5 6 7 8 9 | |
总结:
\是一个特殊字符,它不能再字符串中正常的显示,如果必须显示,就这样写:\\\,不能使用/ 和 // ,使用这两个都是错的,都会导致 DOS找不到指定的文件路径\ ,你写成 \\ 或者 \\\ 或者 \\\\\\ … 对是可以正常执行的,不会出现错误。第二件事 . 同时,我发现:
python 的字符串前面加上r,说明这个字符串是raw string,即无需转义的字符串,意思就是这个字符串里面有什么就是什么。
但是我发现了python的一个bug:
1 2 3 | |
1 2 3 4 | |
1 2 3 4 | |
本篇博客对 Python2 和 Python3 都适用。
参考网站:
1 2 3 4 5 6 7 8 | |
注意:如果想要创建的文件夹是已经存在的,那么执行上面的程序会出现下面的错误:
FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。
所以这段代码容易出现错误:如果文件夹已存在或者文件夹名中有不允许使用的字符时,os.mkdir()函数都会执行失败。所以,这段代码需要进行异常处理:
参考网站:Python 异常处理
1 2 3 4 | |
这样,在运行程序的时候就不会再出现错误了。但是当你给定的文件名中有非法字符时,创建文件夹是不会成功的,但是程序不会报错。
参考网站:Python文件处理 open()
比如你想在F:\根目录里面创建一个名为 data.txt 文件,你可以这样做:
1 2 | |
第二个参数 'w' 也可以写成:'wt'。它们等价。
或者
如果你想创建以指定编码的文件,请参考这篇博客:写文件时,将其用指定的编码方式保存(比如:UTF-8无BOM编码方式)。
参考网站:Python pass 语句
Python2 和 Python3 中 pass 的用法都是一样的。
pass 就是一个空语句,没有任何实际意义,作用是保存程序结构的完整性。
因为Python不像C/C++语言那样,定义一个代码块使用 {}。Python是使用缩进的形式来表述一个代码块的。
比如说想C语言里面的下面这段代码,如果换成Python,怎么写呢?
1 2 | |
换成Python,这样写:
1 2 | |
一个函数,其中带 yield 关键字的代码,它不会执行,只是记下有这个操作;其他代码正常的执行。而被记下的这些操作会像队列一样存起来,这个“队列”就是 生成器,并且会类似于return一样返回。
一个函数的代码里面有 yield 关键字,那么这个函数就是一个制造生成器的函数。
生成器是Python中的高级特性。我之前学习过,还写了一个博客:Learning Python 011 高级特性 2
1 2 3 4 5 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
1 2 3 4 5 6 7 8 9 10 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
生成器在 python2 的用法和在python3中的用法一样,唯一的区别是:
next(g) 或者 g.next()。 这样两个等价next(g),没有g.next()。参考网站:生成器
range() 函数range()函数 知识点Python2 中的range() 函数可以生成一个list。(分配内存空间)
1 2 3 4 | |
Python2 中的xrange()函数不是生成一个list,而是生成一个生成器,不分配内存。
1 2 3 4 5 6 | |
range()函数 知识点1 2 | |
输出:(打印出来的不是一个列表,而是一个生成器)。
Python3 选择这样做的原因:可以节约内存空间,详情请参考这篇博客:Python2和Python3的内存释放。
Python3中的range()函数的功能和Python2中的xrange()函数一样,所以在Python3中没有xrange()函数。
要想生成list或者tuple,这样做:
1 2 3 4 5 6 7 8 9 | |
range()函数的使用下面这段代码在Python2 和 Python3中得到的运行结果都是一样的。
1 2 | |
输出:
1 2 3 4 5 6 7 8 9 10 | |
运行结果是一样的,但是运行的原理不同:
range(10),就生成了一个[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]列表。range(10)时,生成一个元素i。之前我学过很多Python的程序,偶然的一次,我打开任务管理器,看到我写的程序,运行时占用了大量的内存,所以,我希望学会如何释放内存,来优化我的程序,也不给电脑照成太大的负担,所以,我想学会:Python的内存释放这个知识点。
参考网站: gc模块–Python内存释放
下面写几个实验程序,里面都是使用range() 函数来分配内存空间的。range()函数的详细介绍,请见这篇博客:range()函数在python2 和 python3中的使用介绍。
未优化前的代码:
1 2 3 | |

优化内存的代码:
使用手动释放内存的方法来优化内存。
1 2 3 4 5 6 | |
可以看出,占用的内存空间明显减小了。

既优化了内存,也优化了CPU 的代码
使用睡眠来优化CPU运行。
1 2 3 4 5 6 7 8 9 | |

未优化前的代码:
1 2 3 | |
使用Python3库运行未优化的代码,所需要的消耗的内存空间和使用Python2运行优化内存的代码消耗的内存空间 差不多。

优化内存的代码:
1 2 3 4 5 6 | |
可以看出,所暂用的内存空间没有任何增减。

既优化了内存,也优化了CPU 的代码:
1 2 3 4 5 6 7 8 9 | |

Python3 真的是比 Python2 更加的完善了,从这一点上也可以看出来,Python语言是第4代语言里面非常杰出的语言。随着它的不断发展,它会运行速度慢和内存消耗大的缺点会慢慢的消失(因为:许多Python内置库是用C语言写的)。我看好Python。
举一个实例:
Octopress站点路径里面博文文件(.markdown后缀文件)必须要是以UTF-8无BOM编码方式编码的文件,否则执行rake generate命令会出现下面这个错误:
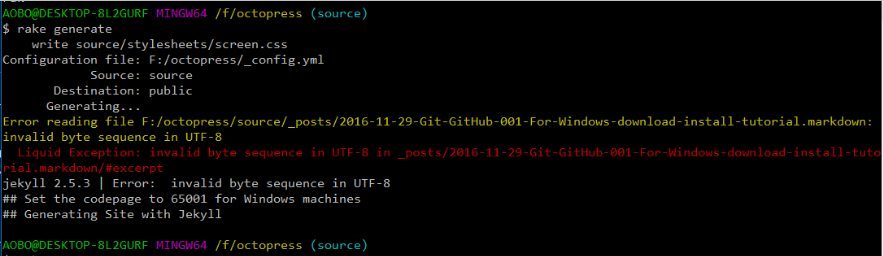
1 2 | |
所以,为了解决不要出现这个问题,我们需要将文件指定你希望的编码方式保存。
其实很简单,我们只需要这样做:
1
| |
这样file文件就是以Utf-8无BOM编码方式编码的文件。
我们也看到了,其实不是将
file保存为以Utf-8无BOM编码方式编码的文件,而是创建这个一个以Utf-8无BOM编码方式编码的文件file。
读取文件时,出现乱码或者UnicodeDecodeError: 'gbk' codec can't decode byte 0xXX in position XX: incomplete multibyte sequence 错误
这两个错误可能会出现一个,两个错误的出现的原因是一样的:当我们使用了一个不正确的编码方式去读取一个不是用这个编码方式编码的文件时,轻者出现乱码,重者出现UnicodeDecodeError错误。
1 2 3 4 5 6 | |
运行输出:
1
| |
1 2 3 4 5 6 | |
运行输出:
1 2 3 4 | |
读取文件时,指定正确的编码方式:
1
| |
现在再运行,就正常了:
1
| |